Exploring CIM - Résultats des sites Luxembourgeois en 2018

Reading time ~ 15 minutes ->
Nous allons aujourd’hui explorer les données récoltées lors du post précédant. Si vous n’avez pas eu l’occasion de lire ce post, je vous invite à le découvrir ici : Récolte des statistiques du CIM avec R et Tidyverse - Luxembourg.
Chargement de tidyverse
Le package tidyverse comprend l’ensemble des libraires nécessaire à l’exploration de données. Le package ggthemes ajoute des thèmes à ggplot.
library(tidyverse)## ── Attaching packages ────────────────────────────────────────────────────────────────────────────────────── tidyverse 1.2.1 ──## ✔ ggplot2 3.1.0 ✔ purrr 0.2.5
## ✔ tibble 2.0.0 ✔ dplyr 0.7.8
## ✔ tidyr 0.8.2 ✔ stringr 1.3.1
## ✔ readr 1.3.1 ✔ forcats 0.3.0## ── Conflicts ───────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()library(ggthemes)7 années de résultats
Préface :
The CIM publishes limited traffic results on its public website. For Belgian websites, Page Views and visits (sessions) are available for Belgian and global traffic within the gemiusOLA platform. In the future limited results on applications and streaming may be added. For Luxembourg websites, there are daily, weekly and monthly reports on Page Views, sessions and Unique Browsers on the CIM website. The technical data (information on browsers, devices, OS, etc.) are aggregated and displayed on country level on the technical ranking website. Belgian results are available via gemius - ranking be and Luxembourgian results are available via gemius - ranking lu.
Avant de commencer, récupérons la base de donnée constitée précédemment :
cim <- readRDS("data/cim2011_2018.rds")Résumons le contenu des données. On y retrouve 6 variables pour 244.975 entrées du 30 mars 2011 au 31 décembre 2018 :
date: le jour de la mesuresite: le site concernétype: Classification :- Site
- Application Site
category:- B2b
- Classified automotive
- Classified immo
- Culture et entertainement radio
- News
- Portal
- Service directories
metrics: les différentes statistiques :- pages_by_session : Le nombre de pages par sessions
- pages_view : Le nombre de page vues
- sessions : Le nombre de sessions
- session by user : Le ratio entre le nombre des sessions et le nombre d’utilisateurs (unique_visitors)
- unique_visitors : le nombre d’utilisateurs ou (cookie)
glimpse(cim)## Observations: 244,975
## Variables: 6
## $ date <date> 2011-03-30, 2011-03-30, 2011-03-30, 2011-03-30, 2011-0…
## $ site <chr> "atHome.lu", "atOffice.lu", "Editus", "Eldoradio", "L'e…
## $ type <chr> "Site", "Site", "Site", "Site", "Site", "Site", "Site",…
## $ category <chr> "Classified immo", "Classified immo", "Service director…
## $ metrics <chr> "unique_visitors", "unique_visitors", "unique_visitors"…
## $ hits <dbl> 9772, 360, 21762, 7581, 30437, 11822, 12798, 3173, 7099…Duplication de données
En générant un graphique rapide sur l’ensemble des données, nous pouvons observer un problème entre 2014 et 2015, un résultat improbable.
cim %>%
ggplot() +
aes(date, hits, group1 = site, group2 = metrics) +
geom_line(alpha = 0.4) +
annotate("segment", xend = as.Date("2014-07-10"), x = as.Date("2015-06-01"), y = 16582427, yend = 16582427, colour = "red", arrow = arrow(length = unit(0.3, "cm"))) +
theme_solarized_2() +
theme(axis.text.y = element_blank())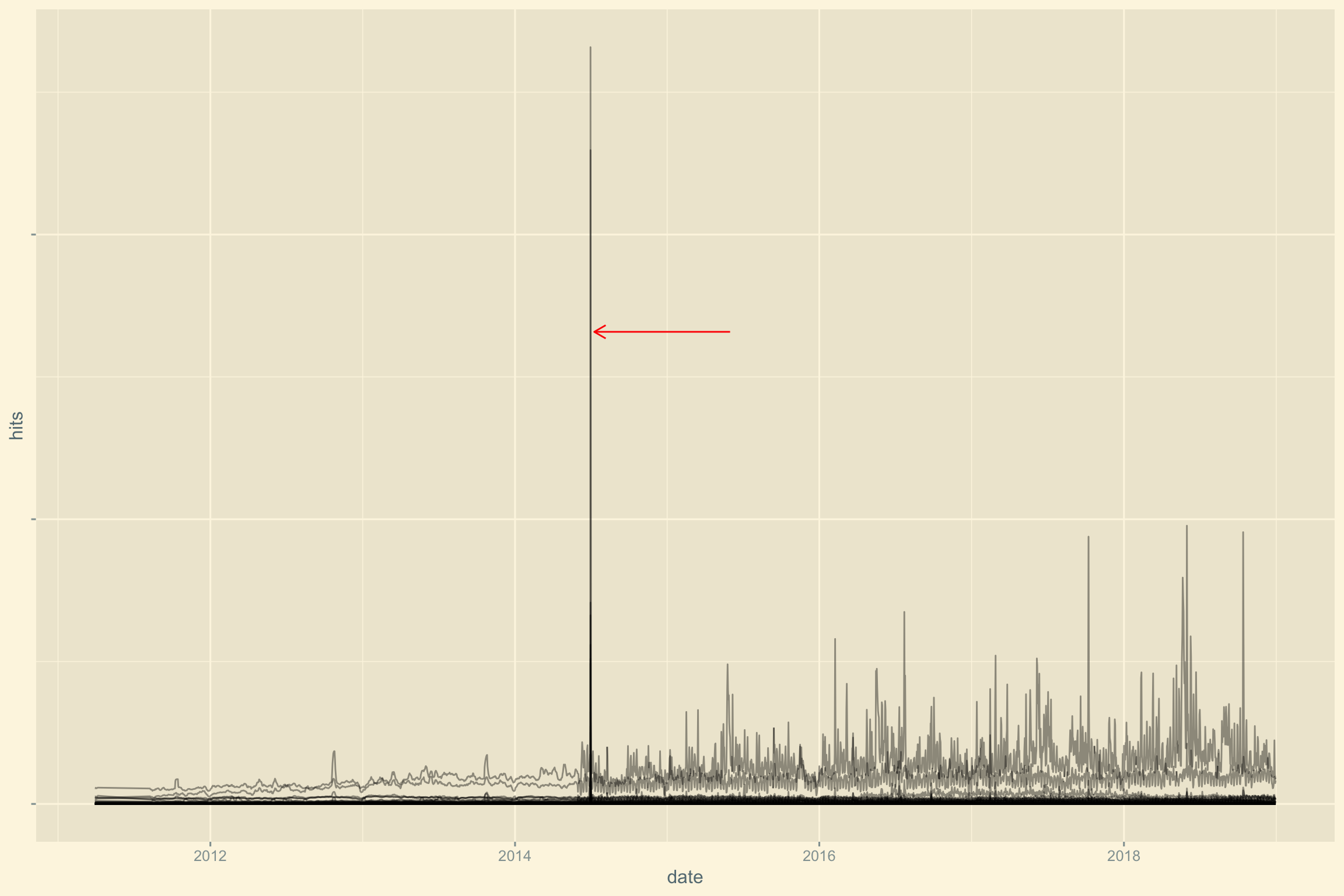
Pour vérifier cela, affichons la valeur maximale encodée.
cim %>% filter(hits == max(hits))## # A tibble: 1 x 6
## date site type category metrics hits
## <date> <chr> <chr> <chr> <chr> <dbl>
## 1 2014-07-01 RTL Luxembourg Site News pages_view 2658242726.658.427 pages vues le 1 juillet 2014. Vérifions s’il existe plusieurs entrées pour ce site à la même date.
cim %>% filter(site == "RTL Luxembourg") %>% filter(date == "2014-07-01")## # A tibble: 10 x 6
## date site type category metrics hits
## <date> <chr> <chr> <chr> <chr> <dbl>
## 1 2014-07-01 RTL Luxembourg Site News unique_visitors 92571
## 2 2014-07-01 RTL Luxembourg Site News unique_visitors 856928
## 3 2014-07-01 RTL Luxembourg Site News sessions 163369
## 4 2014-07-01 RTL Luxembourg Site News sessions 4928658
## 5 2014-07-01 RTL Luxembourg Site News pages_view 1043933
## 6 2014-07-01 RTL Luxembourg Site News pages_view 26582427
## 7 2014-07-01 RTL Luxembourg Site News pages_by_session 6.4
## 8 2014-07-01 RTL Luxembourg Site News pages_by_session 5.4
## 9 2014-07-01 RTL Luxembourg Site News sessions_by_user 1.8
## 10 2014-07-01 RTL Luxembourg Site News sessions_by_user 5.8Ouch! On voit effectivement le problème.
Gather et Spread ne sont pas symétriques
Souvenez-nous, lors de l’extraction de données, nous avions utiliser la fonction gather() afin d’avoir une variable par colonne. Que se passe-t-il si nous voulons revenir en arrière ? Utilisons gather() pour étendre la table.
La fonction nous renvoie un message d’erreur. Nous avons des entrées dupliquées. Nous pouvons mieux comprendre ce qui se passe en observant le problème rencontré plus haut. Pour une même date, même site (donc même catégorie et type), nous avons pour les sessions 2 mesures. Lors de la transformation de la table avec spread() les 6 valeurs de la variable metrics s’étendent, mais la fonction ne sait pas comment réagir face à ces 2 entrées. Quelle mesure (nombres de sessions par ex.) attribuer à la variable (session) ? La plus élevée?
Pour résoudre ce problème, nous allons supprimer les valeurs max pour chaque date. Nous allons utiliser la fonction group_by() afin de grouper les variables ensemble et pour chaque élément du groupe, ne conserver que min(hits) avec la fonction summarize().
cim %>%
group_by(date, site, type, category, metrics) %>%
summarize(hits = min(hits)) %>%
head(5)## # A tibble: 5 x 6
## # Groups: date, site, type, category [1]
## date site type category metrics hits
## <date> <chr> <chr> <chr> <chr> <dbl>
## 1 2011-03-30 atHome.lu Site Classified immo pages_by_session 34.4
## 2 2011-03-30 atHome.lu Site Classified immo pages_view 257135
## 3 2011-03-30 atHome.lu Site Classified immo sessions 7481
## 4 2011-03-30 atHome.lu Site Classified immo sessions_by_user 0.8
## 5 2011-03-30 atHome.lu Site Classified immo unique_visitors 9772Appliquons à nouveau la fonction spread().
cim %>%
group_by(date, site, type, category, metrics) %>%
summarize(hits = min(hits)) %>%
spread(metrics, hits) %>%
head(5)## # A tibble: 5 x 9
## # Groups: date, site, type, category [5]
## date site type category pages_by_session pages_view sessions
## <date> <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 2011-03-30 atHo… Site Classif… 34.4 257135 7481
## 2 2011-03-30 atOf… Site Classif… 23.6 7333 311
## 3 2011-03-30 Edit… Site Service… 3.9 71761 18572
## 4 2011-03-30 Eldo… Site Culture… 21.1 107086 5080
## 5 2011-03-30 L'es… Site News 11.4 232154 20299
## # … with 2 more variables: sessions_by_user <dbl>, unique_visitors <dbl>Ca marche! Nous voyons ici que la manipulation fonctionne. Pas de message d’erreur. Nous avons pour chaque date et pour chaque site, 5 entrées :
- pages_by_session
- pages_view
- sessions
- session by user
- unique_visitors
Conservons la version tidy dans une nouvelle table :
cim2 <- cim %>%
group_by(date, site, type, category, metrics) %>%
summarize(hits = min(hits))Revoyons maintenant le graphique : BAM! 1er problème réglé.
cim2 %>%
ggplot() +
aes(date, hits, group1 = site, group2 = metrics) +
geom_line(alpha = 0.4) +
theme_solarized_2() +
theme(axis.text.y = element_blank())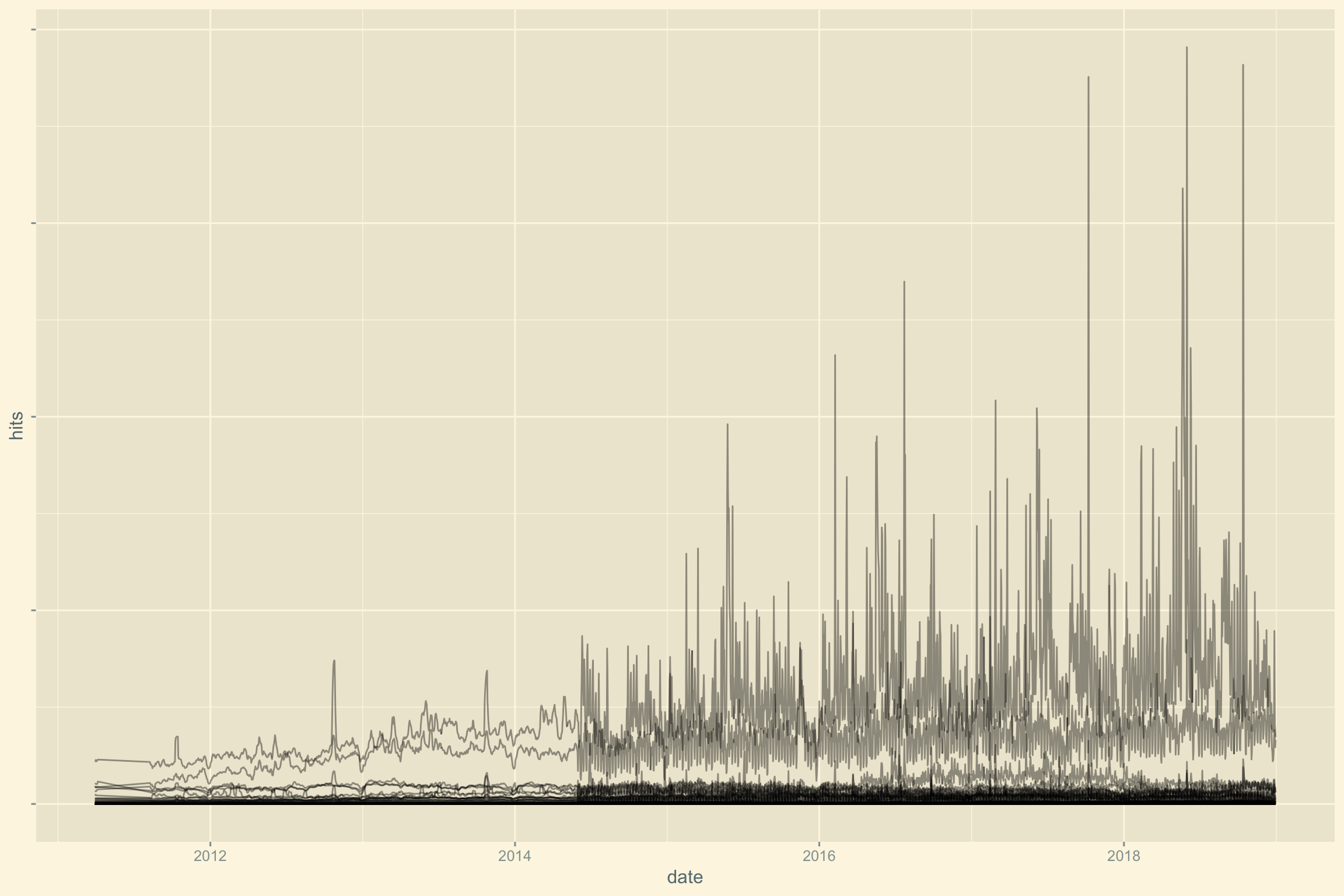
D’autres problèmes ?
Voyons l’évolution des sessions dans le temps. Nous observons un changement significatif entre 2014 et 2015 marqué par une ligne verticale rouge.
cim2 %>%
filter(metrics == "sessions") %>%
ggplot() +
aes(date, hits, group1 = site, group2 = metrics) +
geom_line(alpha = 0.4) +
geom_vline(xintercept = as.Date("2014-06-01"), col = "red") +
theme_solarized_2() +
theme(axis.text.y = element_blank())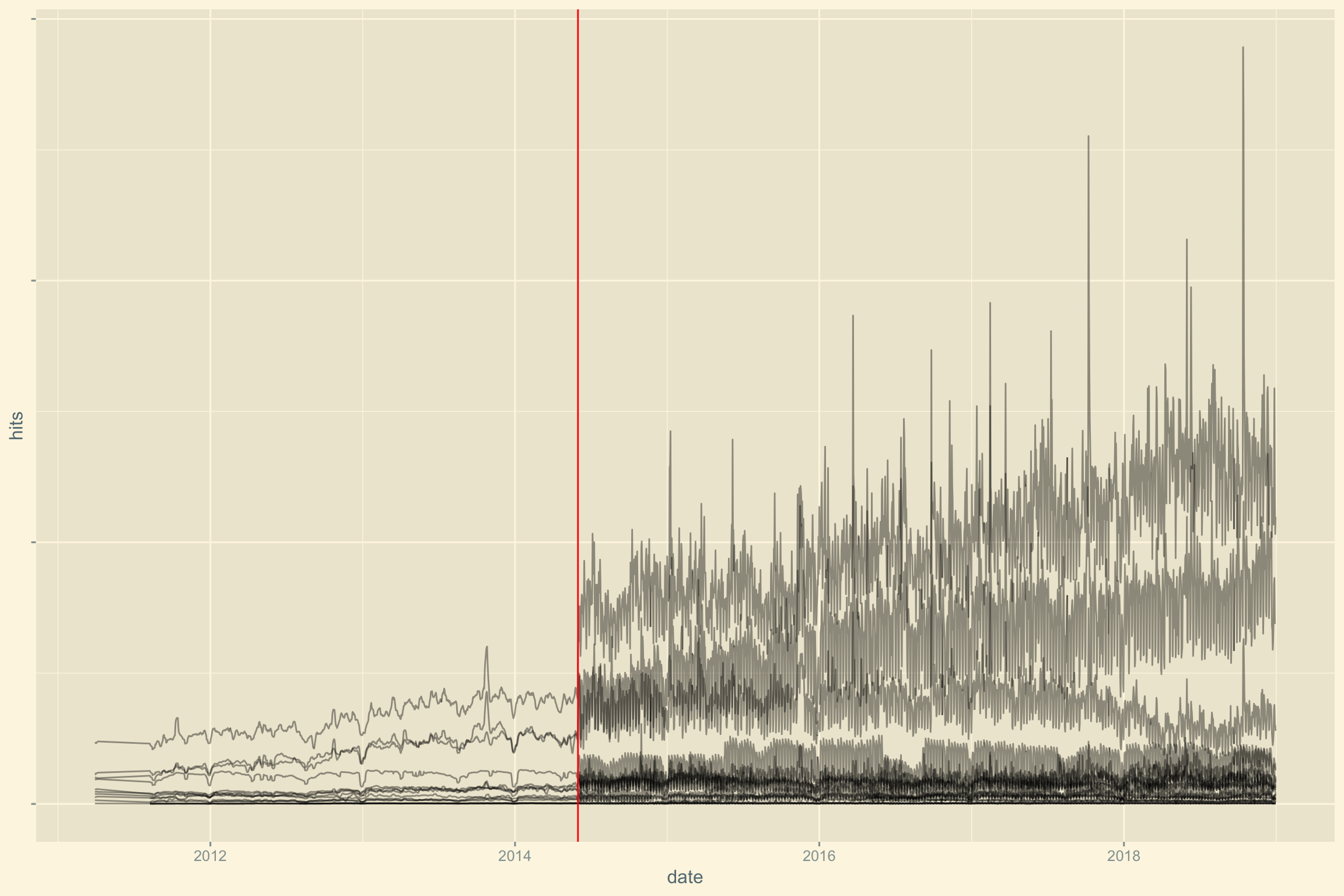
Zoomons sur le problème. Il semblerait qu’une nouvelle méthodologie de mesure ait été utilisée à partir de juin 2014.
cim2 %>%
filter(metrics == "sessions") %>%
filter(date > "2014-04-01", date < "2014-07-01") %>%
ggplot() +
aes(date, hits, group = site) +
geom_line(alpha = 0.4) +
geom_vline(xintercept = as.Date("2014-06-01"), col = "red") +
theme_solarized_2() +
theme(axis.text.y = element_blank())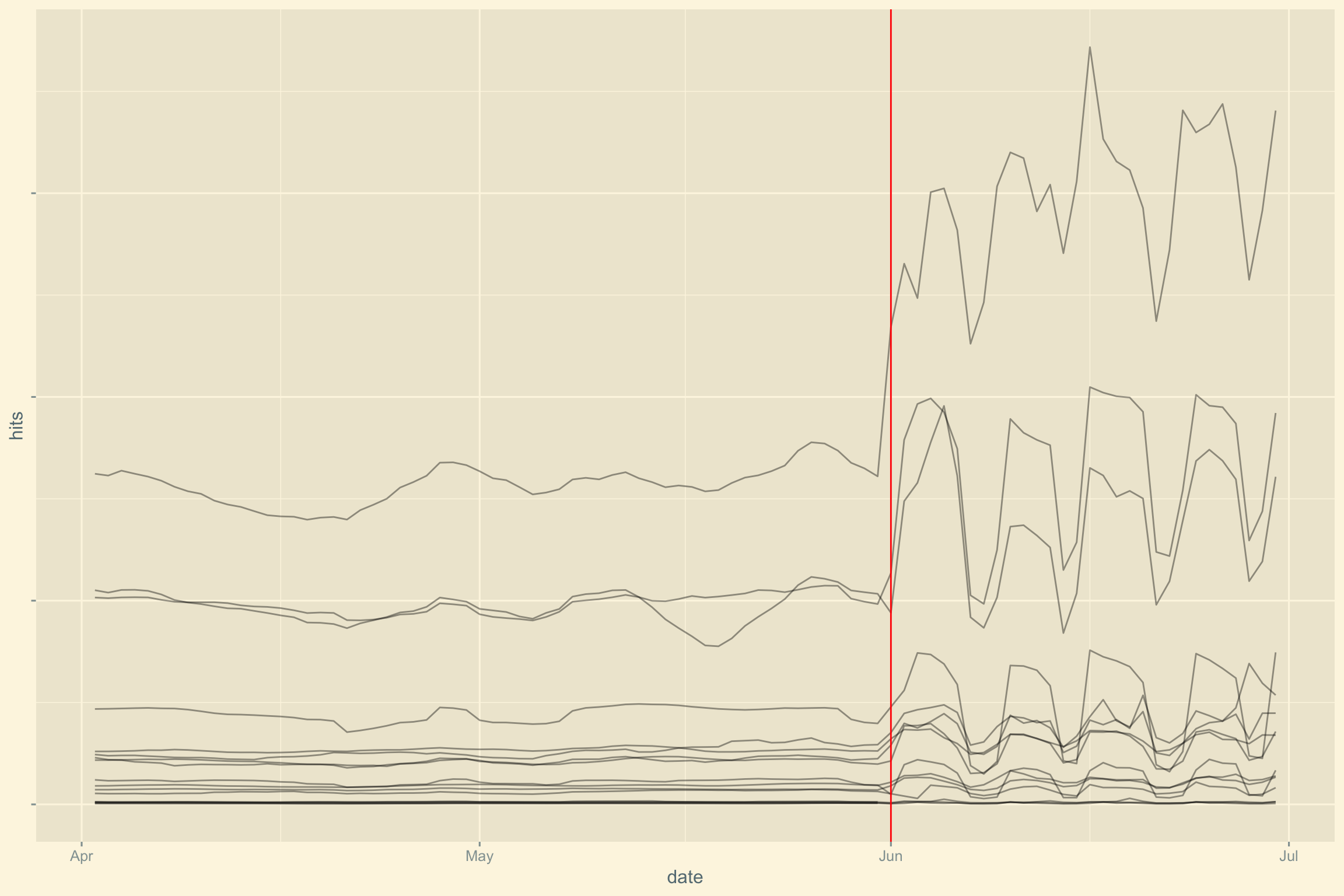
Posons la question par twitter. Nous verons bien s’ils répondent :-)
@CIM_InfoMedia Que s'est-il passé dans vos données sur #Luxembourg en juin 2014? Savez-vous aussi que vous avez de multiples entrées pour les mêmes dates? pic.twitter.com/kO6WnGYlpF
— David Solito (@dsolito) January 12, 2019
Quelle performance pour chaque site ?
Nous allons explorer la performance de chaque site et générer un graphique. Étant donné l’écart entre les différentes metrics, nous générerons un graphique par metric avec facet_wrap(). Pour cela nous allons utiliser la fonction map() pour itérer sur chaque groupe de metrics par site. Pour y arriver nous passerons par la fonction nest().
1. nest()
cim2 %>%
group_by(site) %>%
nest()## # A tibble: 21 x 2
## site data
## <chr> <list>
## 1 atHome.lu <tibble [13,500 × 5]>
## 2 atOffice.lu <tibble [13,500 × 5]>
## 3 Editus <tibble [13,495 × 5]>
## 4 Eldoradio <tibble [13,500 × 5]>
## 5 L'essentiel <tibble [13,500 × 5]>
## 6 Luxauto <tibble [13,360 × 5]>
## 7 Luxweb.com <tibble [13,500 × 5]>
## 8 PaperJam <tibble [13,500 × 5]>
## 9 RTL Luxembourg <tibble [13,500 × 5]>
## 10 Wort.lu <tibble [13,500 × 5]>
## # … with 11 more rows2. Utilisation de map()
Nous “mappons” la fonction ggplot() sur la colonne data créée par nest(). La fonction plucknous permet de sortir le graphique souhaité. facet_wrap permet de générer un graphique par métrique.
cim2 %>%
group_by(site) %>%
nest() %>%
mutate(graph = map(data, ~ ggplot(.x)
+ aes(date, hits, col = metrics) + geom_point(alpha = 0.05, col = "black")
+ facet_wrap(. ~ metrics, scale = "free")
+ theme_solarized_2())
) %>%
pluck(3, 8) #extract graph 8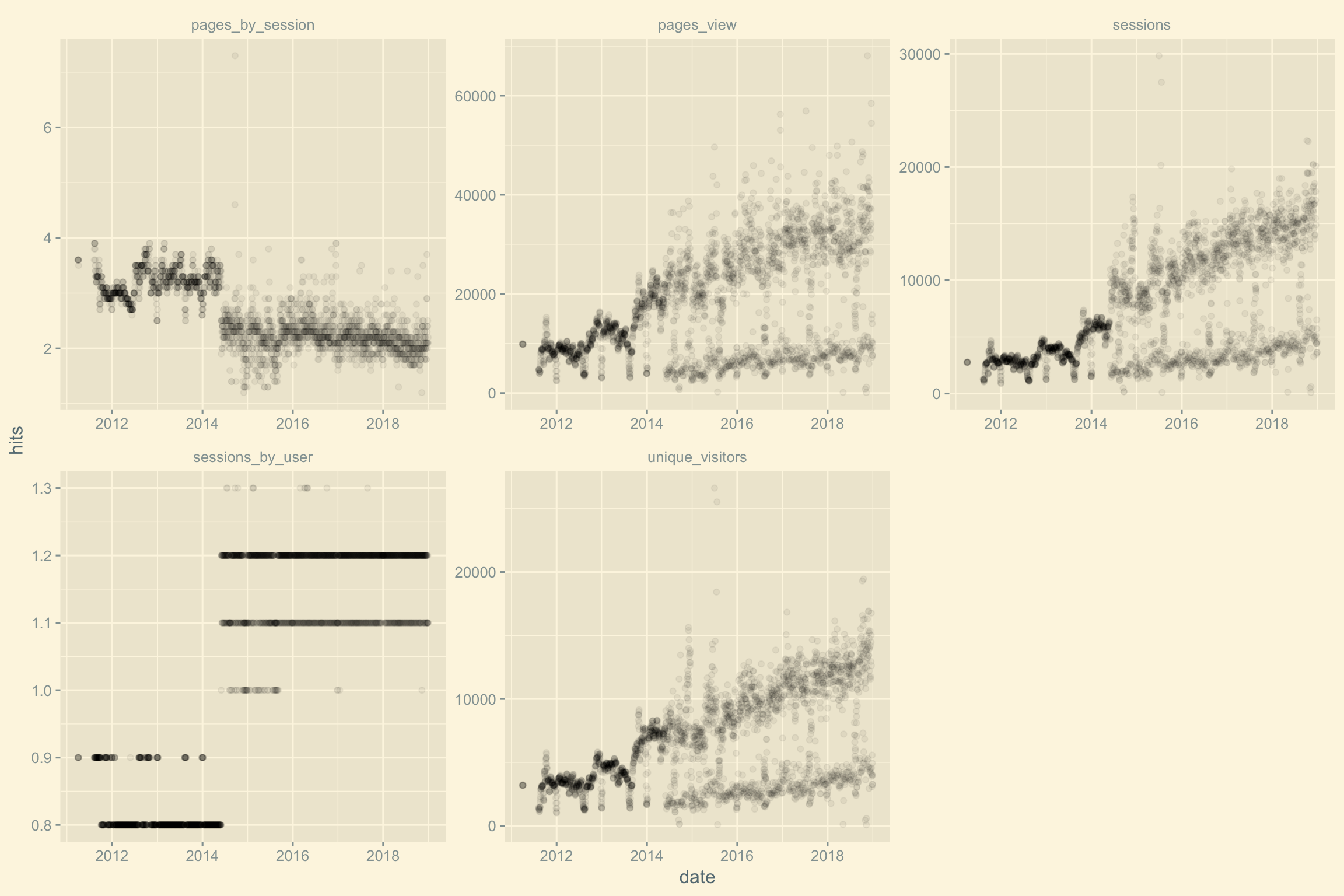
Voilà, ça fonctionne ! Mais il manque quelque chose… Le titre du graphique. Nous avons vu précédemment que map utilise la fonction ggplot avec les paramètres pour générer chaque graphique. Pour simplifier le code, nous allons wrapper l’ensemble des paramètres de ggplot dans une fonction avec as_mapper(). Observer l’utilisation de .y en plus de .x pour la génération des titres du graphique. En effet, map2() permet d’utiliser 2 variables.
my_sexy_ggplot <- as_mapper( ~ ggplot(.x)
+ aes(date, hits, col = metrics)
+ geom_line(alpha = 0.1, col = "black")
+ geom_point(alpha = 0.1, col = "black")
+ geom_smooth(se = FALSE, size = 0.7)
+ labs(title = .y)
+ ggthemes::theme_solarized_2()
+ theme(axis.text.x = element_text(angle = 90))
+ theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm"))
+ scale_color_pander()
+ facet_wrap(. ~ metrics, scale = "free")
+ labs(title = paste("Mesures CIM -", .y),
subtitle = "Regression locale (LOESS)",
x = "", y = "hits per day ",
caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018")
)Allons-y. Donc pour .x -> data, .y -> site. Ajoutons notre fonction sexy :-). Nous avons aussi ajouté une régression locale (LOESS) afin d’avoir une intuition de la moyenne sur la période observée. Cela nous évite de calculer la moyenne de la semaine ou du mois sur l’ensemble de la période. Nous pouvons observer dans les mesures 2 grappes. Cela correspond aux jours de la semaine versus le week-end. Nous pourrions par ex. séparer les résultats en fonction des jours.
cim2 %>%
group_by(site) %>%
nest() %>%
mutate(graph = map2(data, site, my_sexy_ggplot)) %>%
pluck(3, 8) #extract graph 8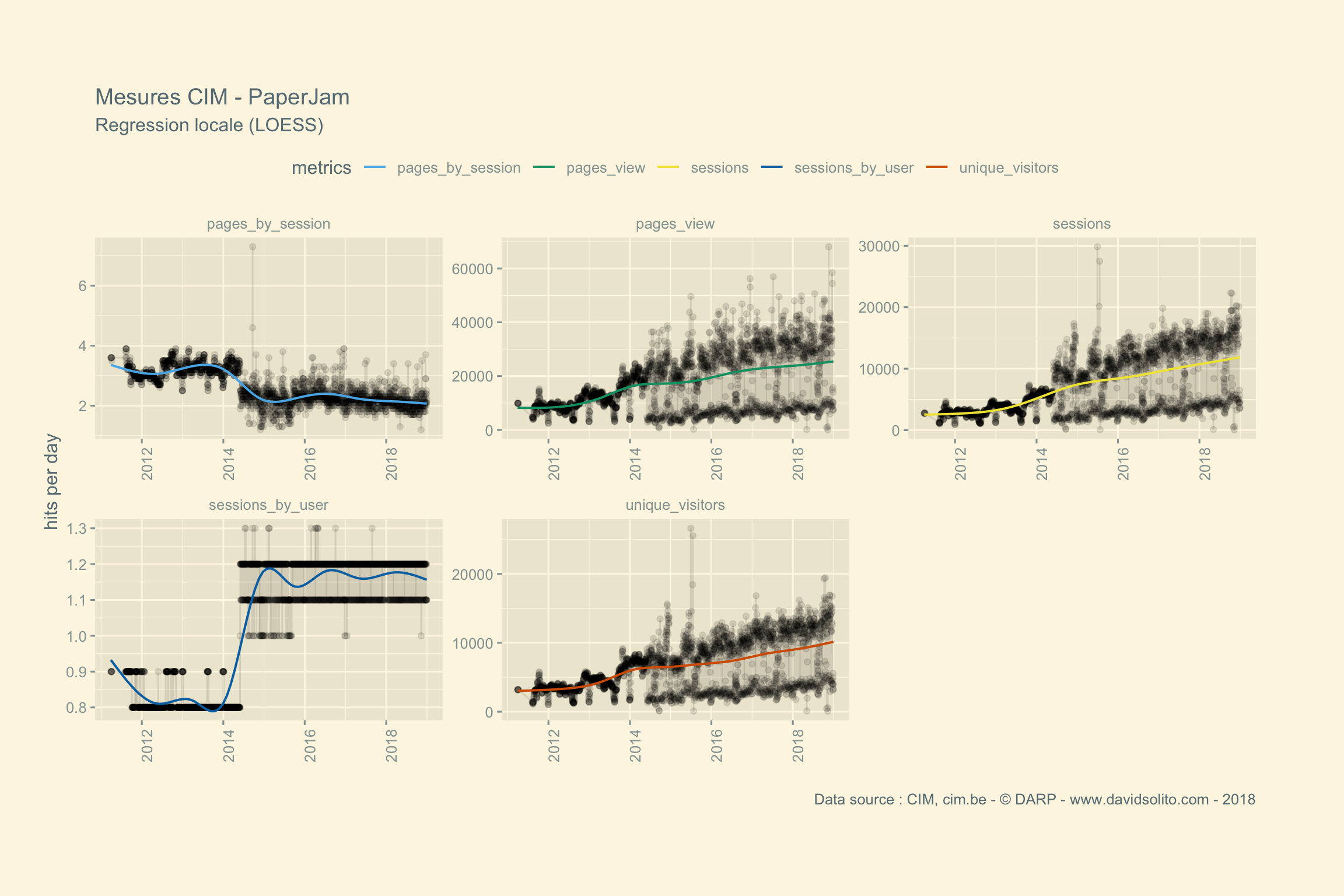
Boom ! Utilisons pull() pour sortir l’ensemble des graphiques. Pas mal, non?
cim2 %>%
group_by(site) %>%
nest() %>%
mutate(graph = map2(data, site, my_sexy_ggplot)) %>%
pull() ## [[1]]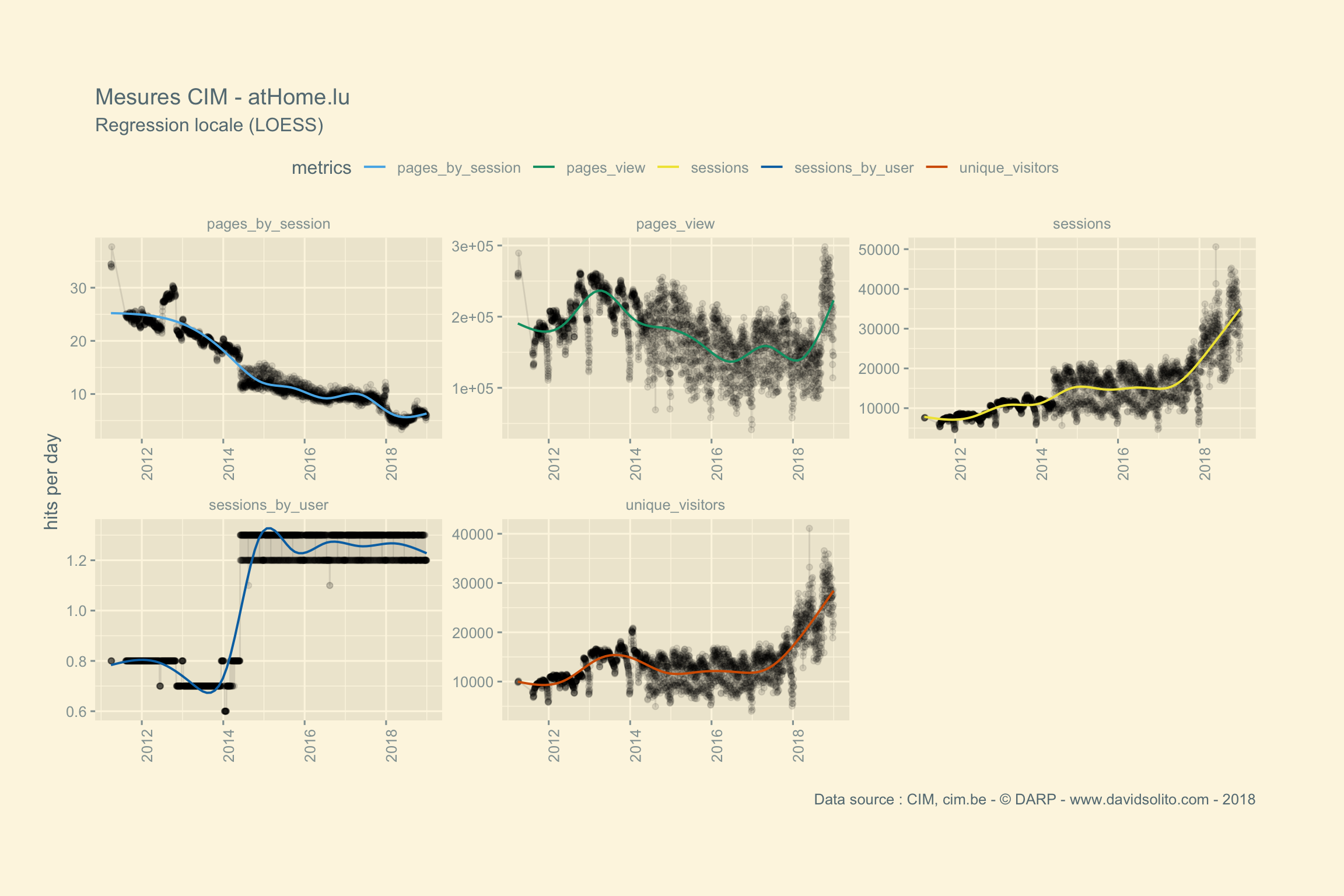
##
## [[2]]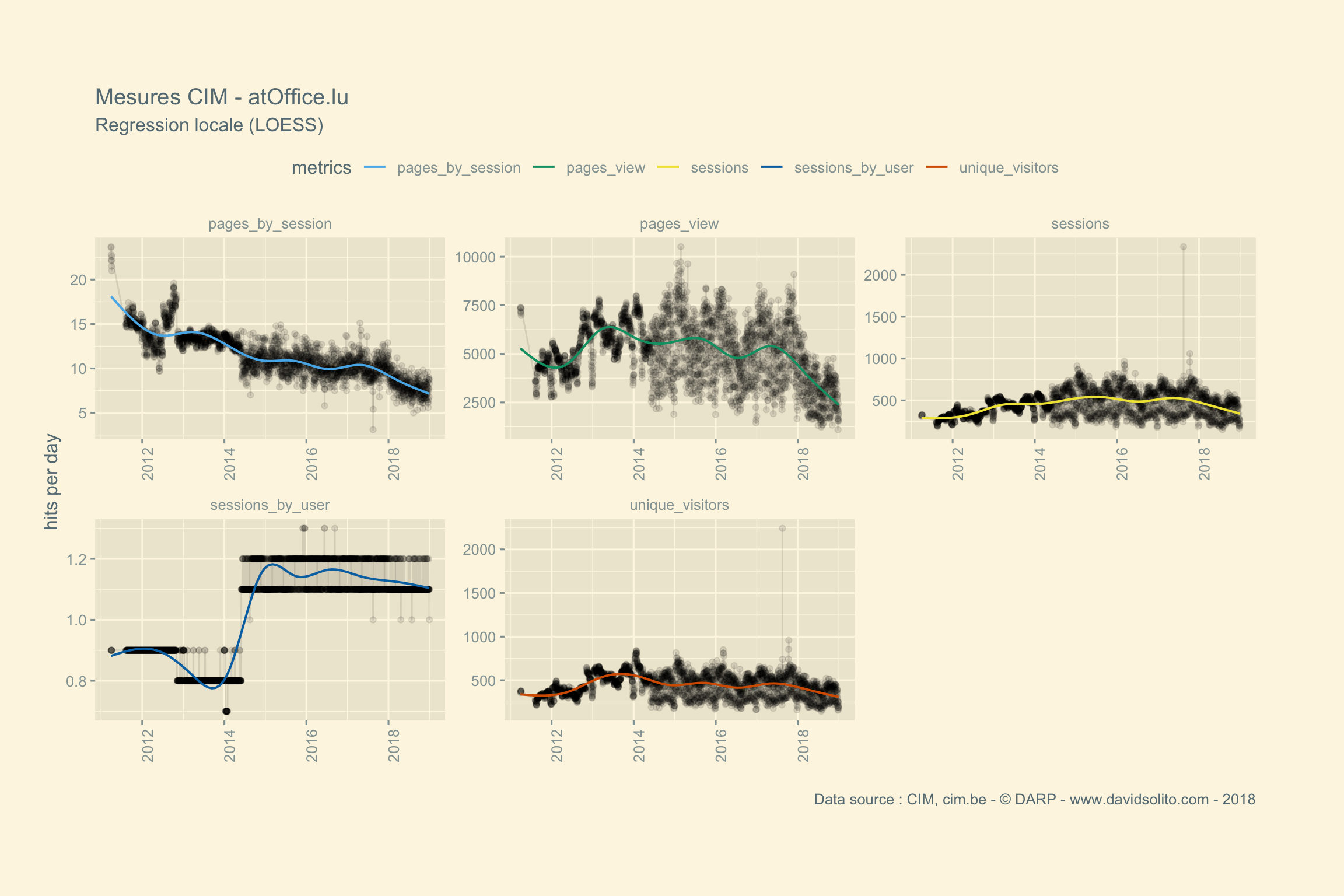
##
## [[3]]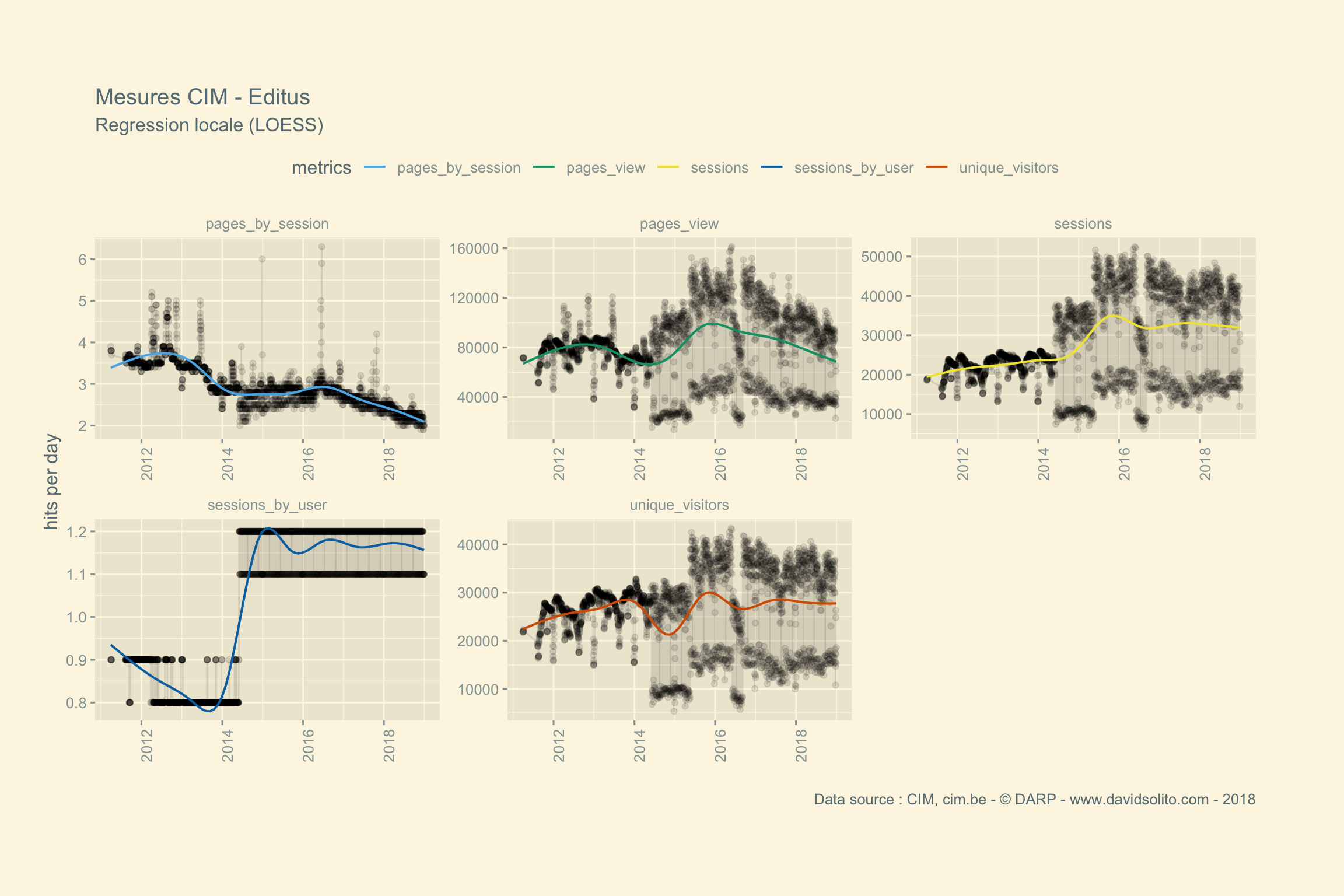
##
## [[4]]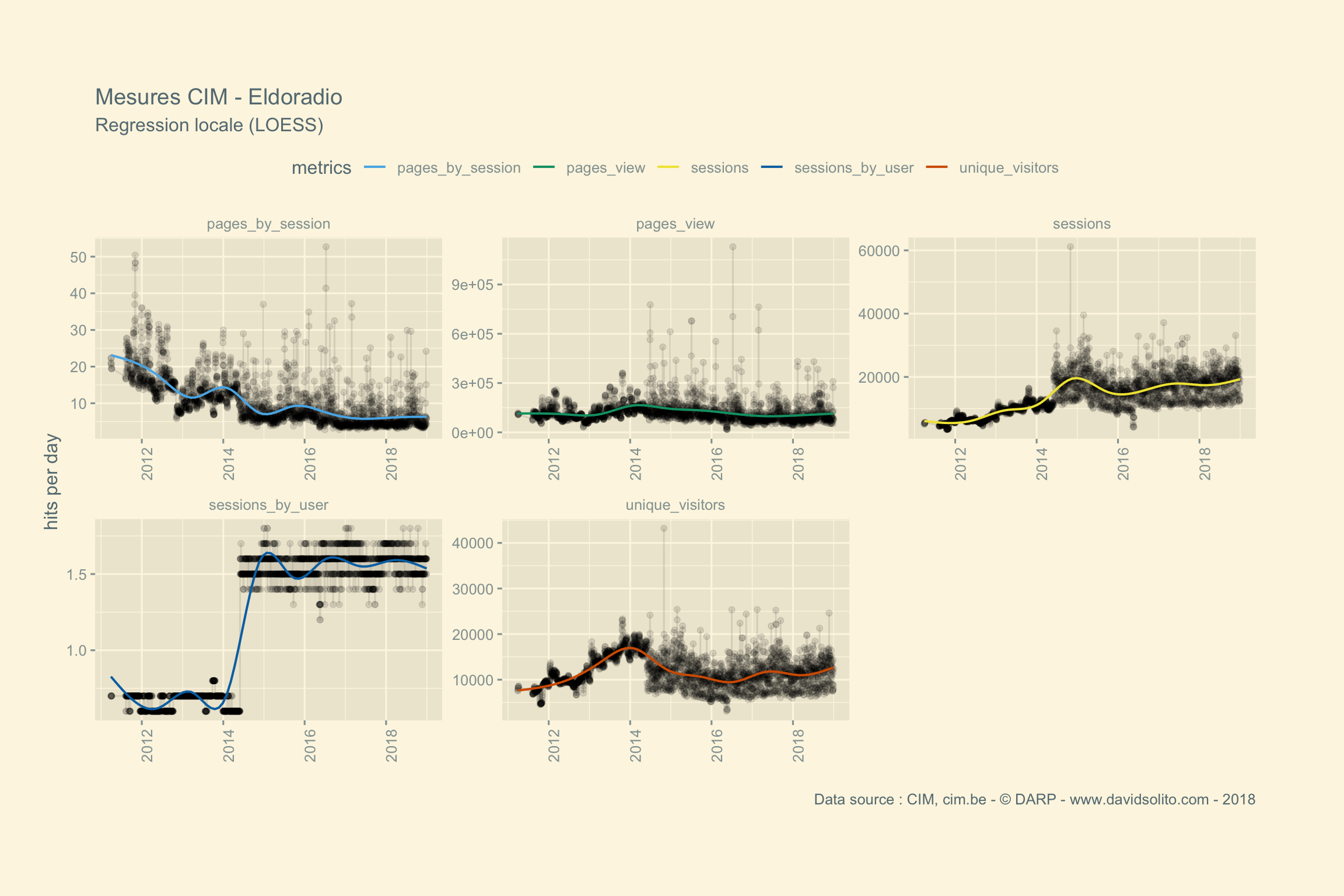
##
## [[5]]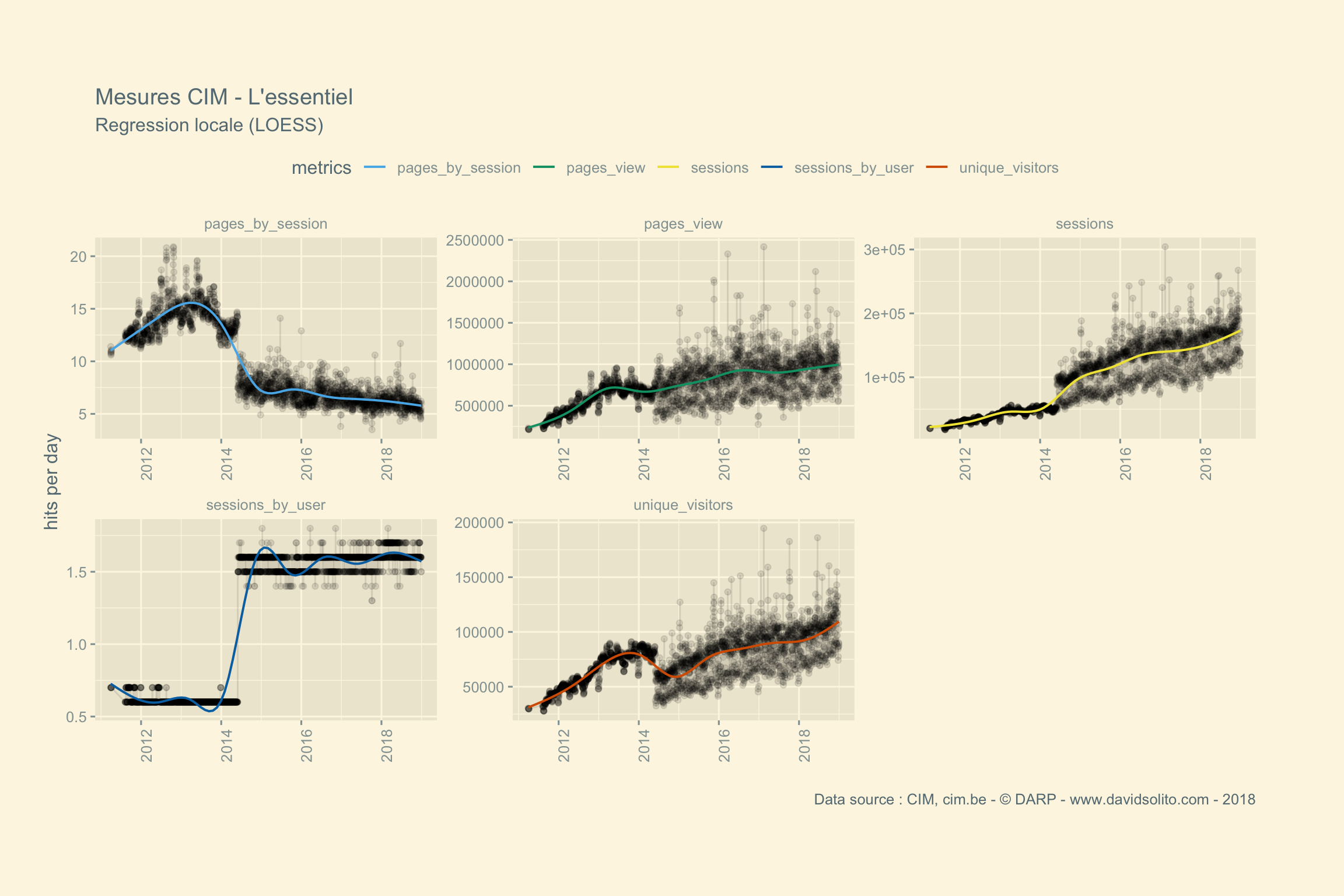
##
## [[6]]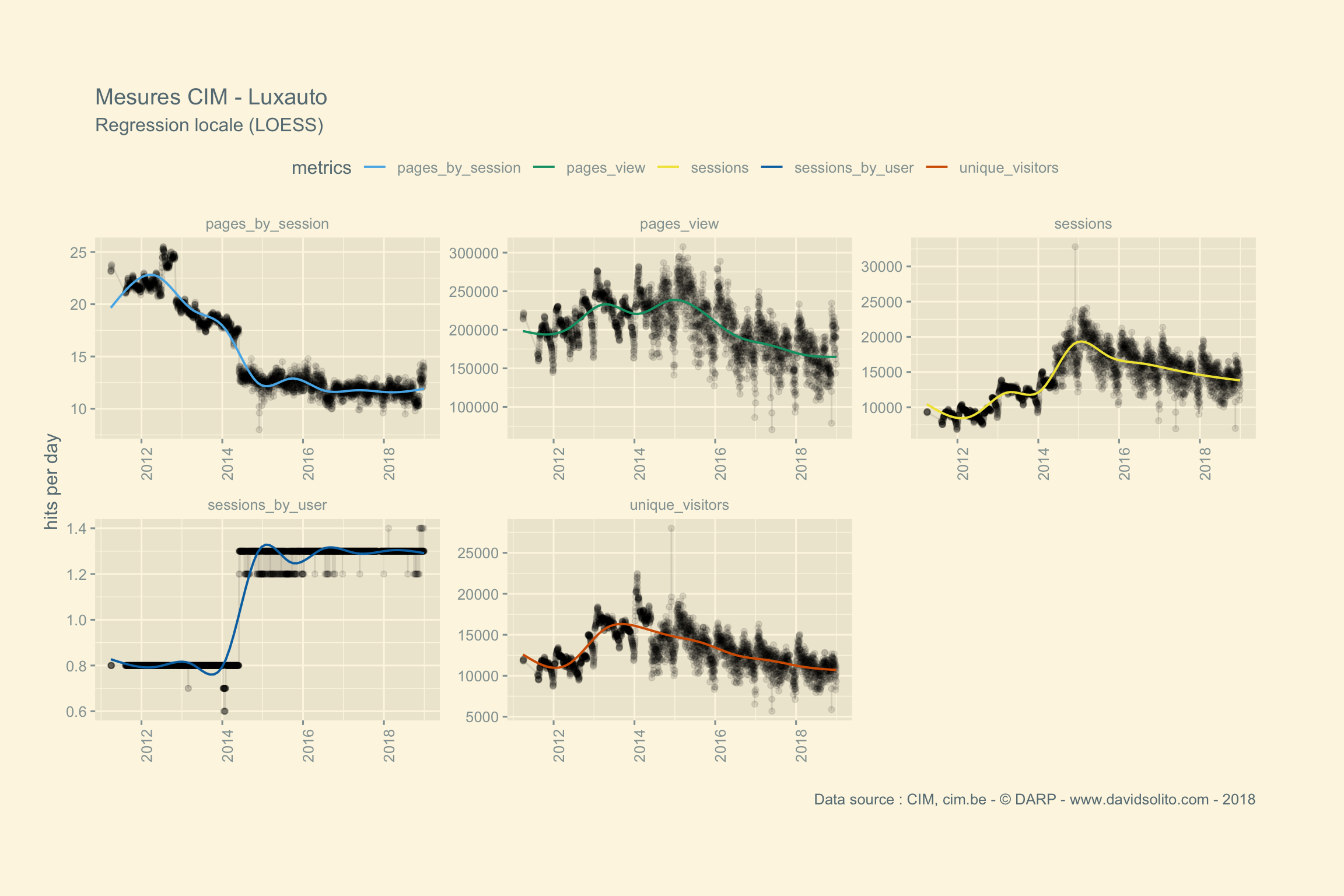
##
## [[7]]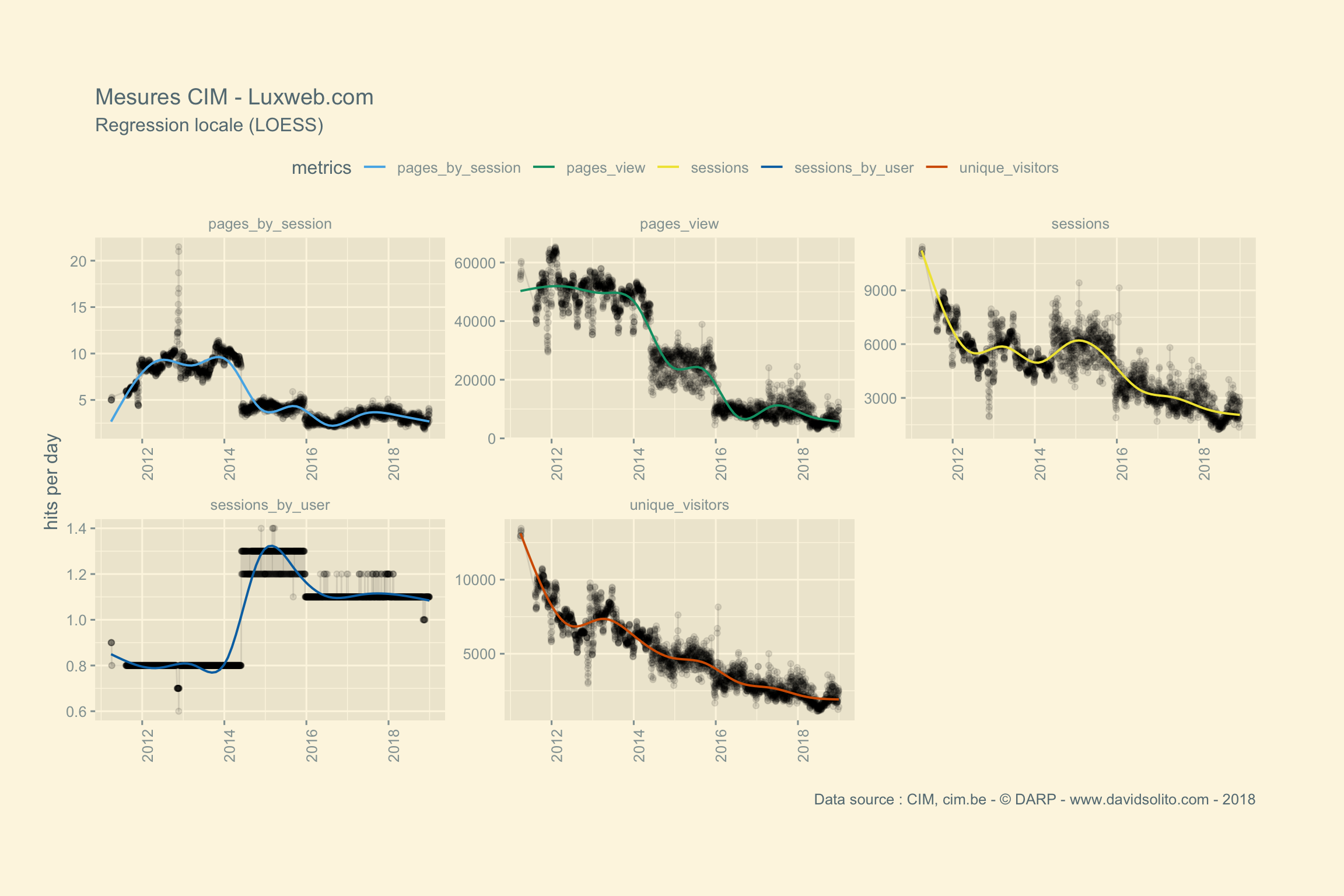
##
## [[8]]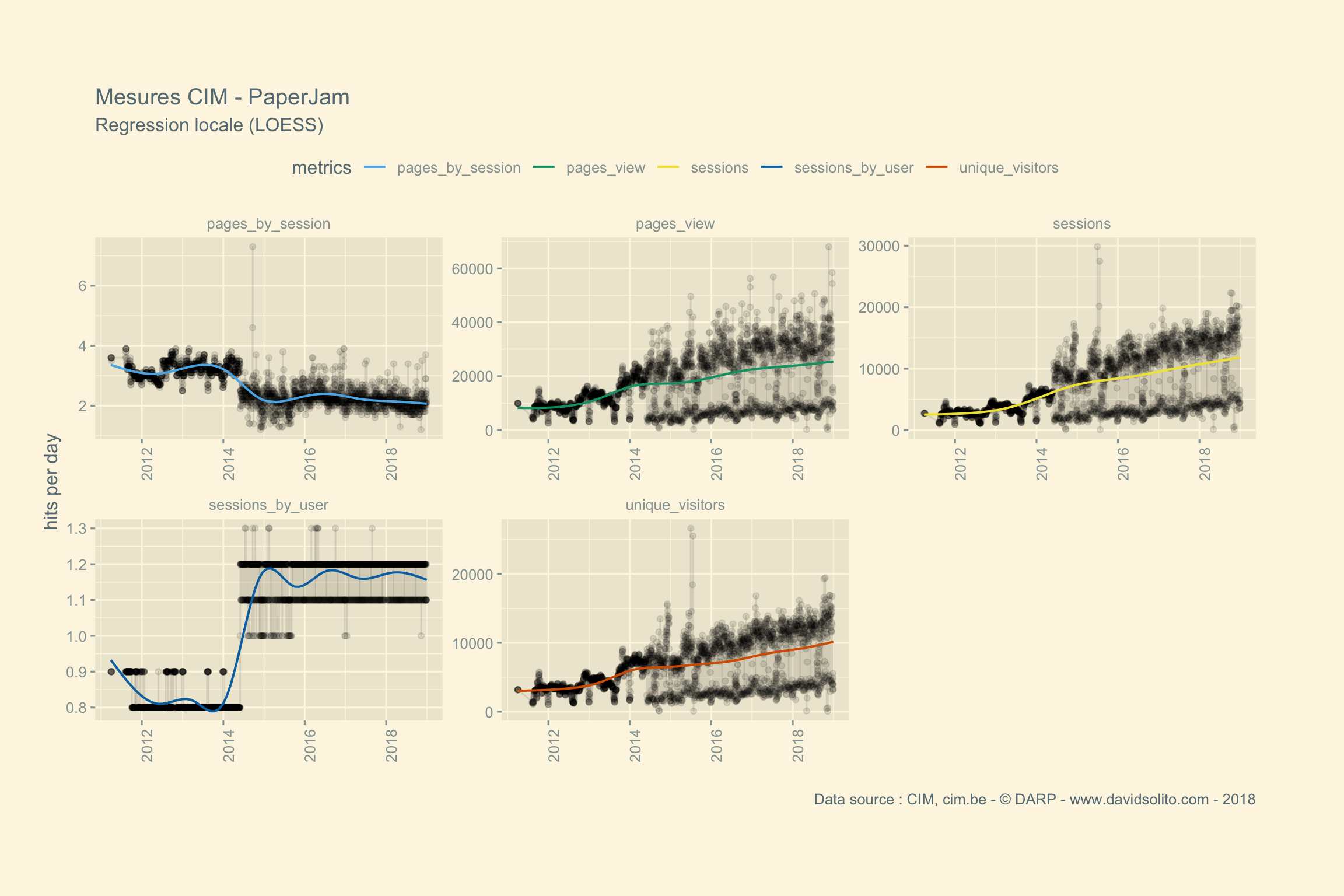
##
## [[9]]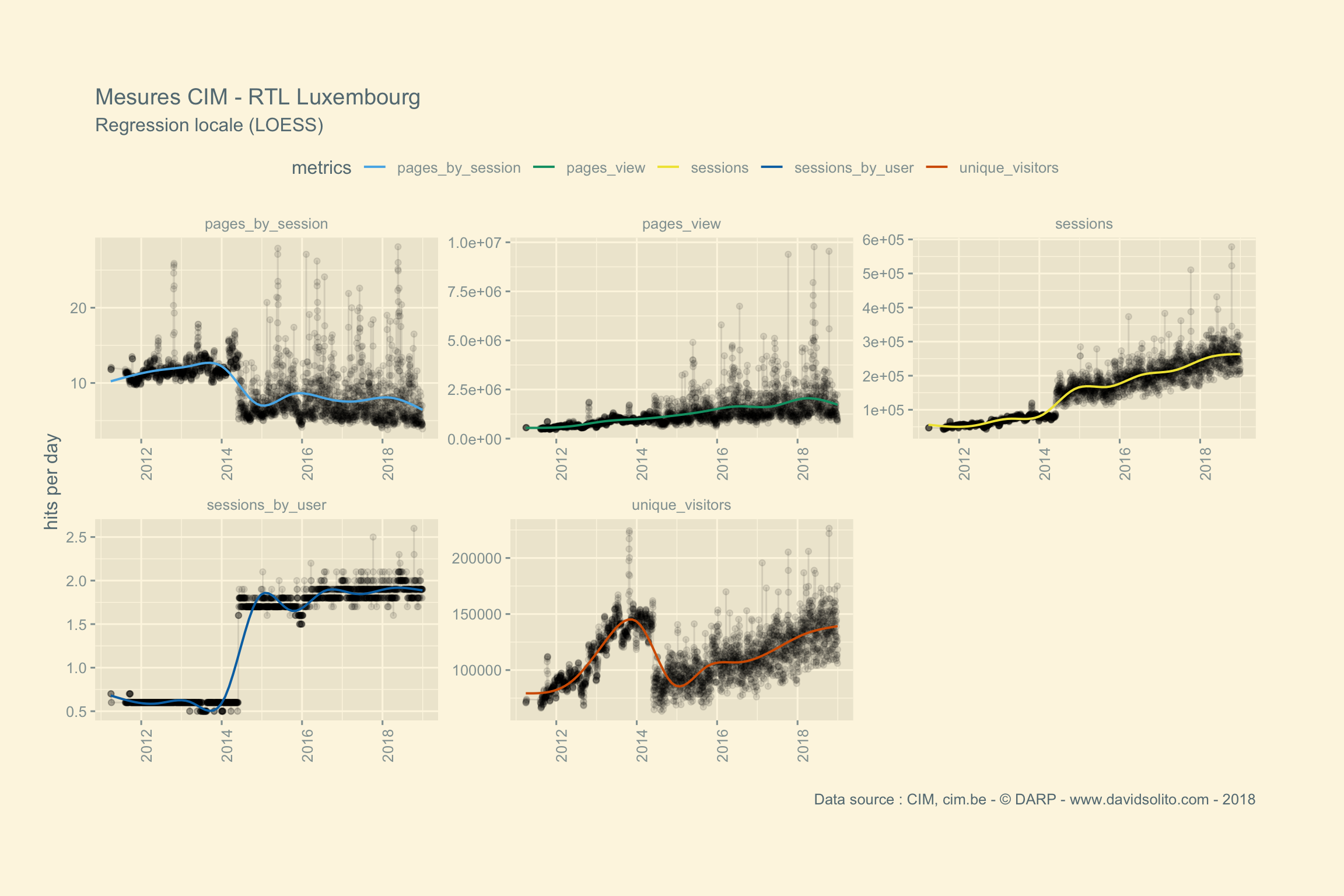
##
## [[10]]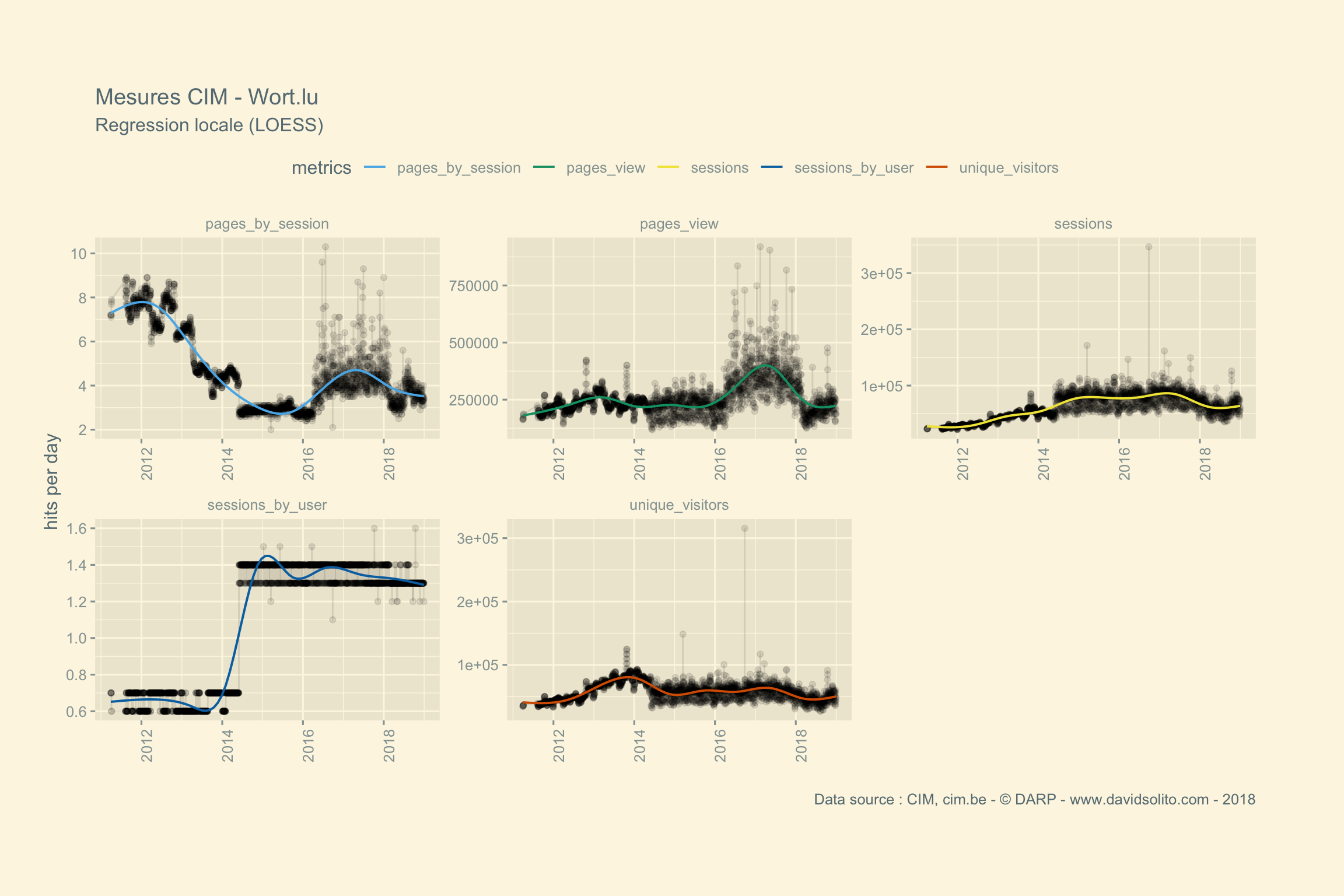
##
## [[11]]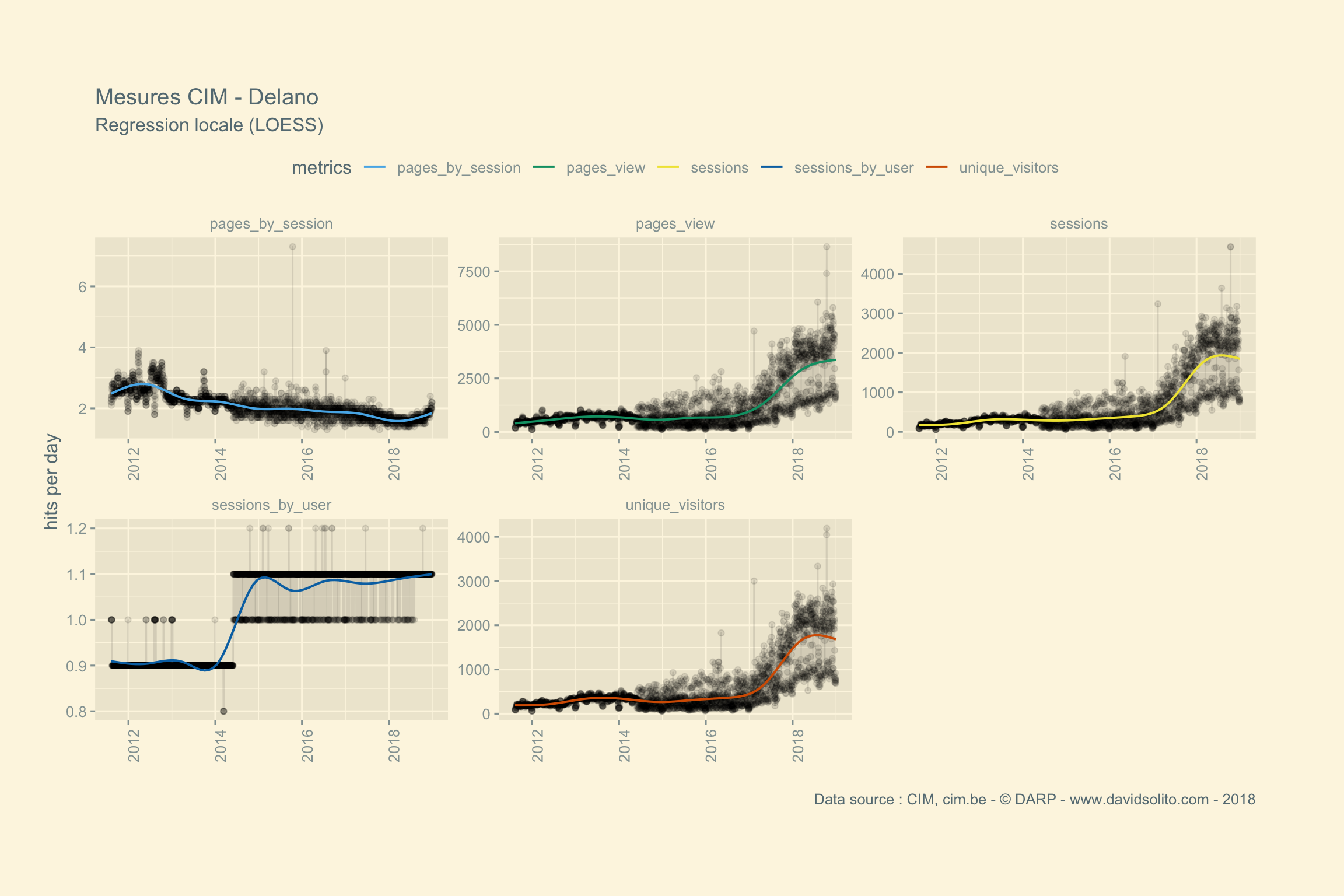
##
## [[12]]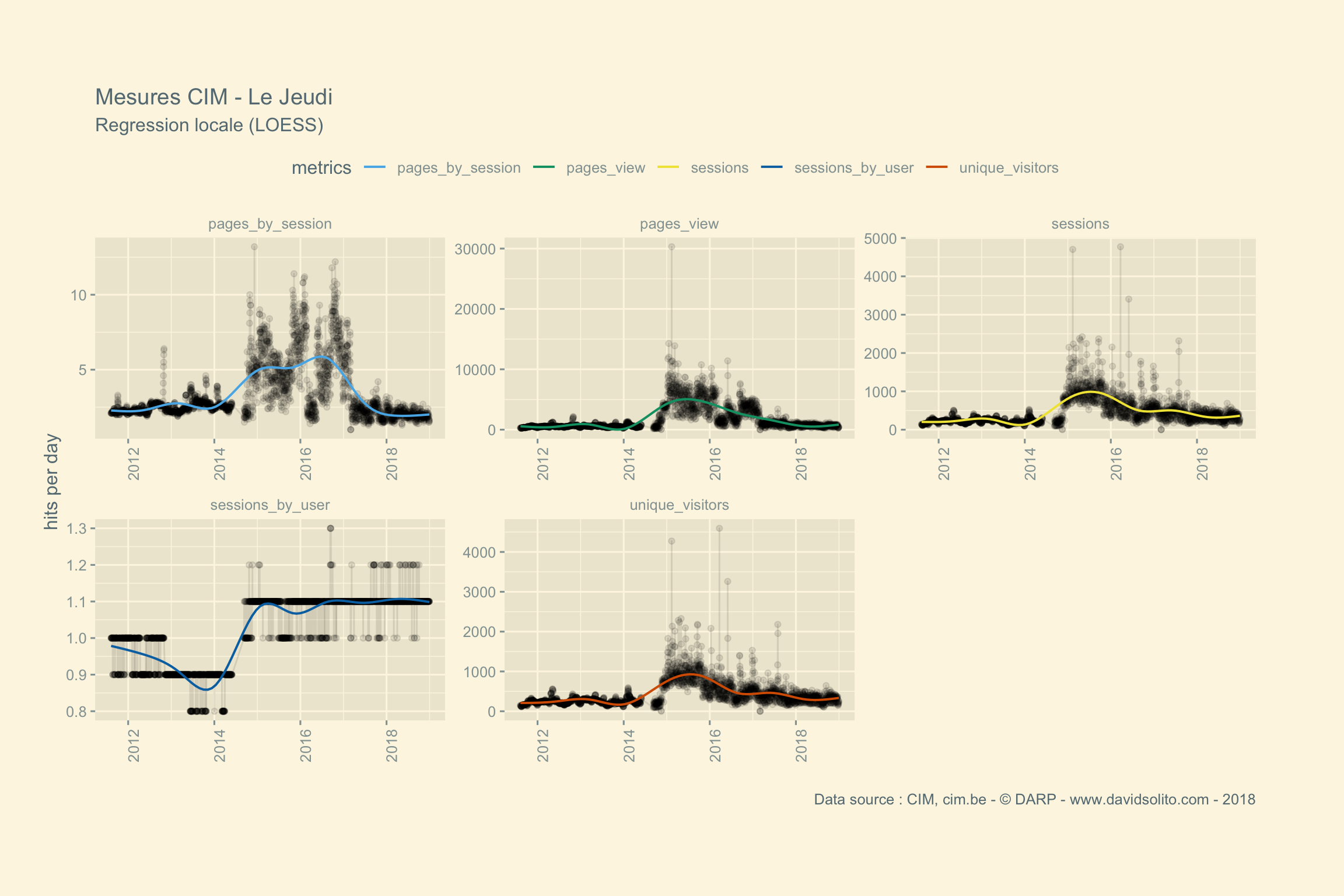
##
## [[13]]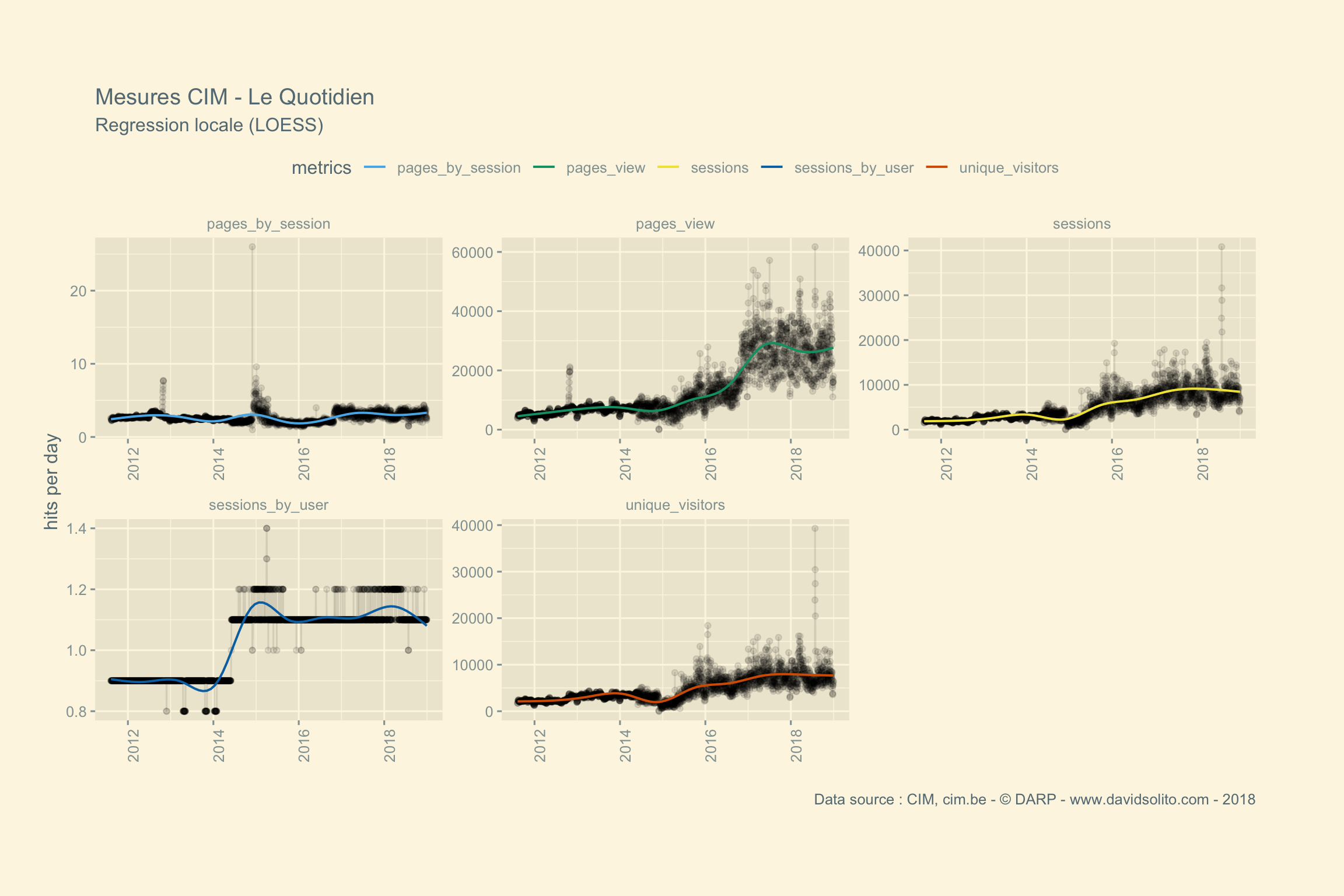
##
## [[14]]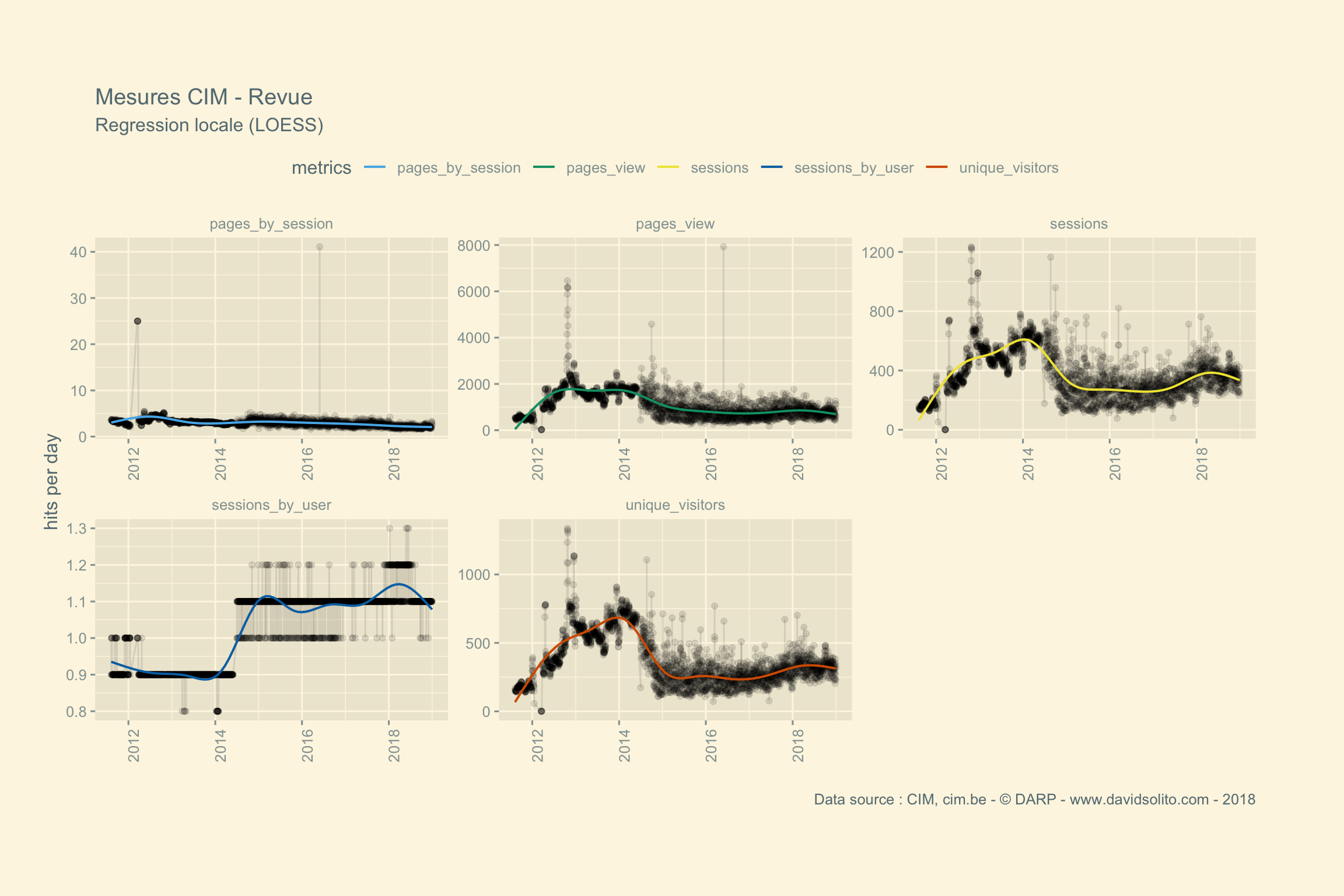
##
## [[15]]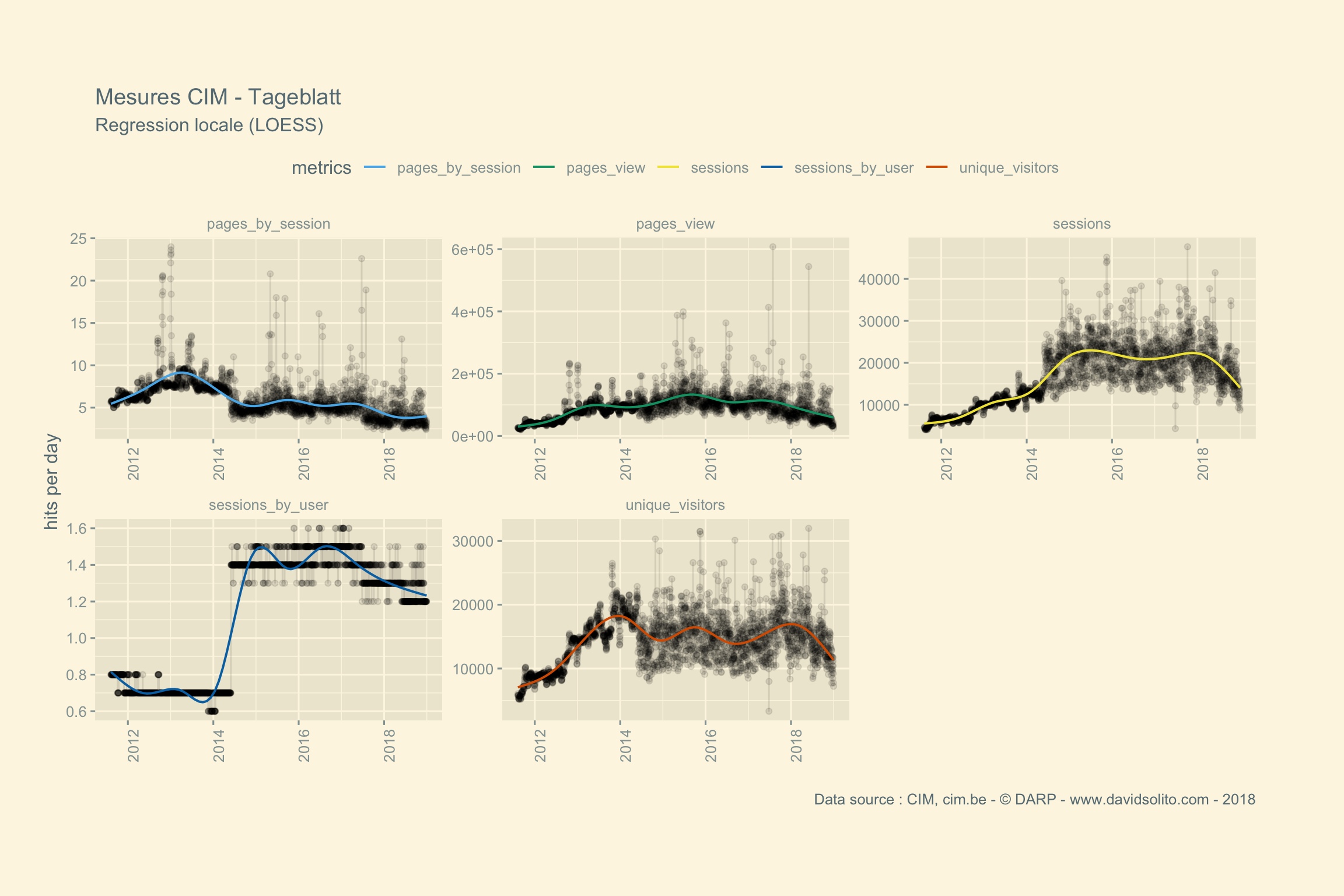
##
## [[16]]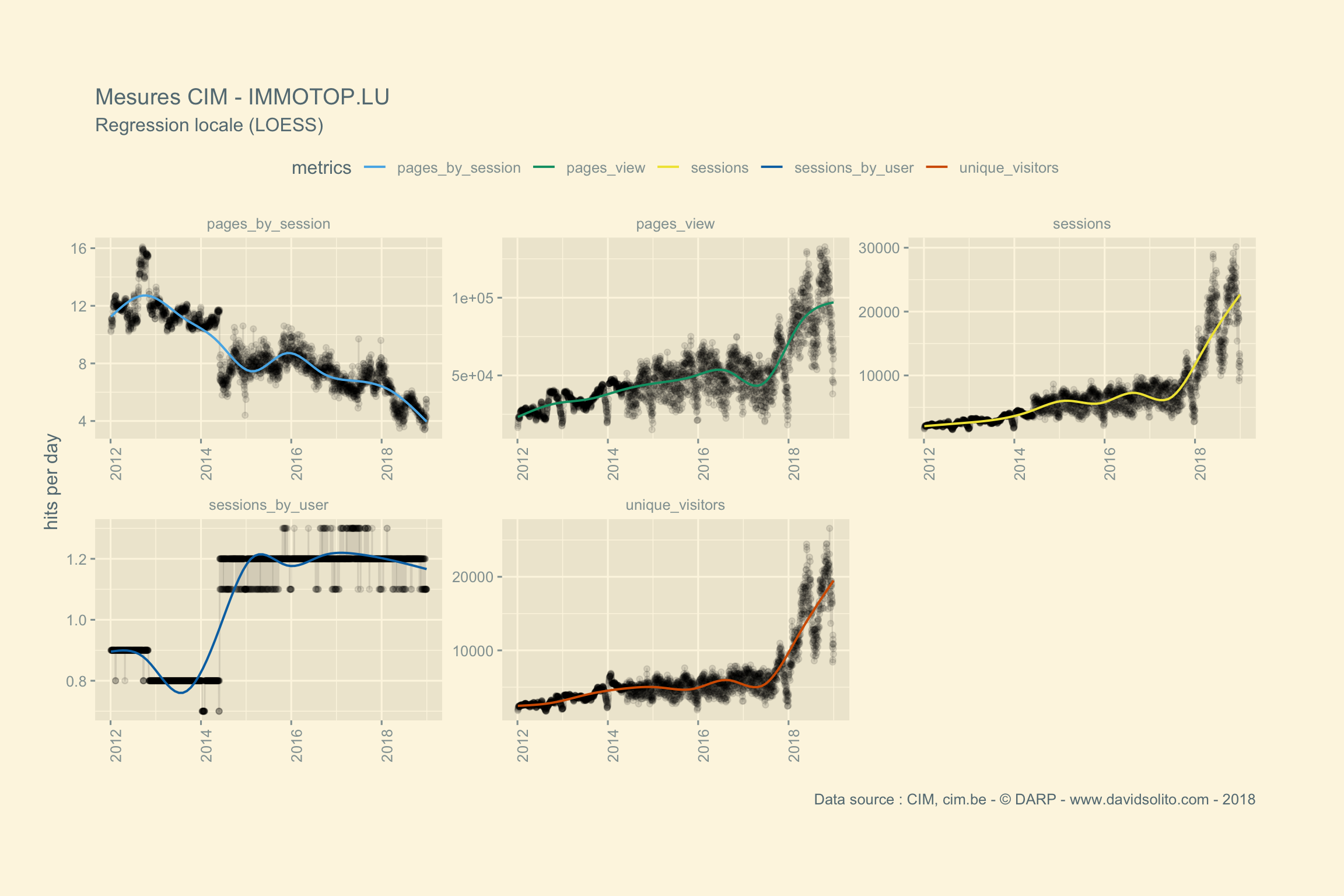
##
## [[17]]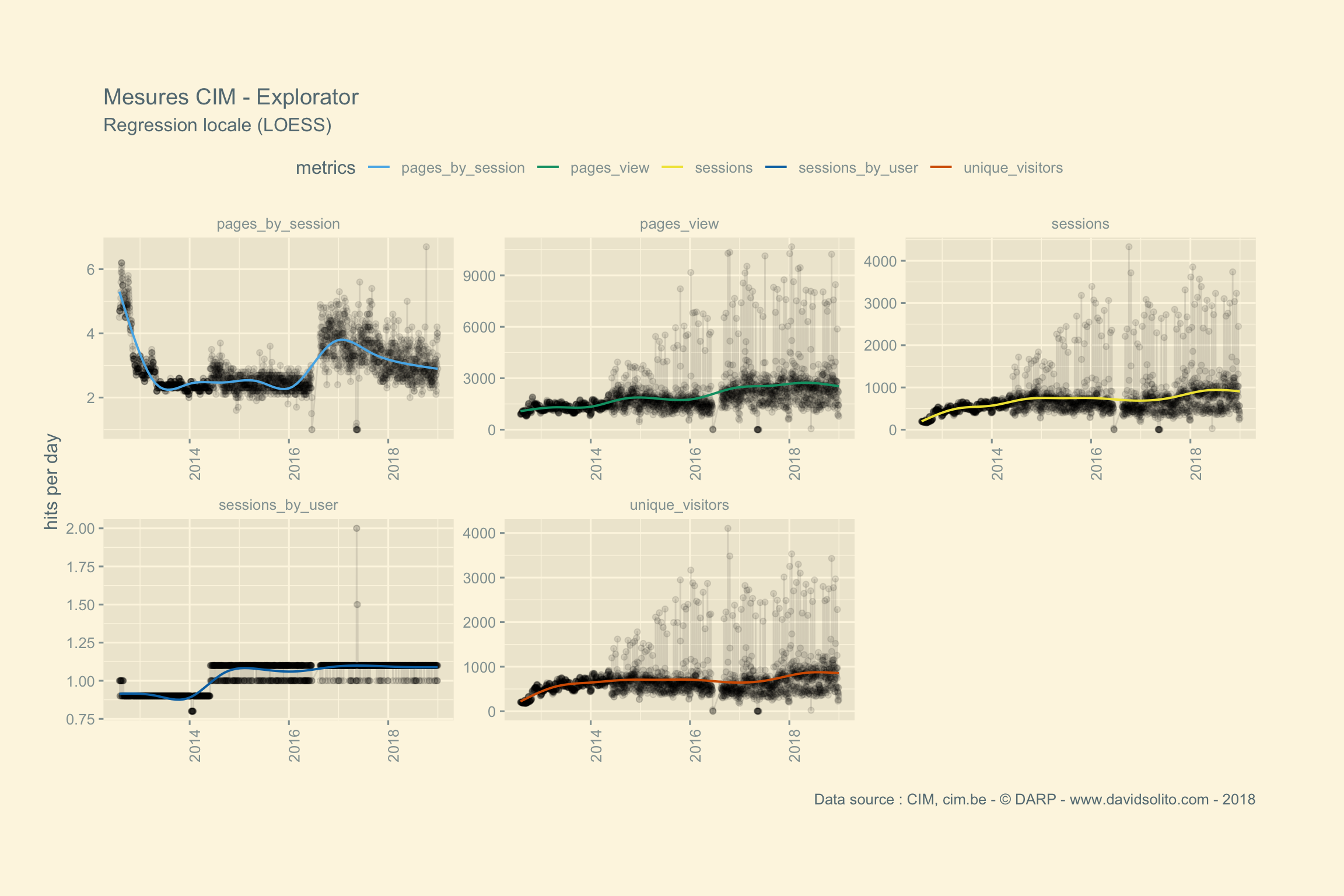
##
## [[18]]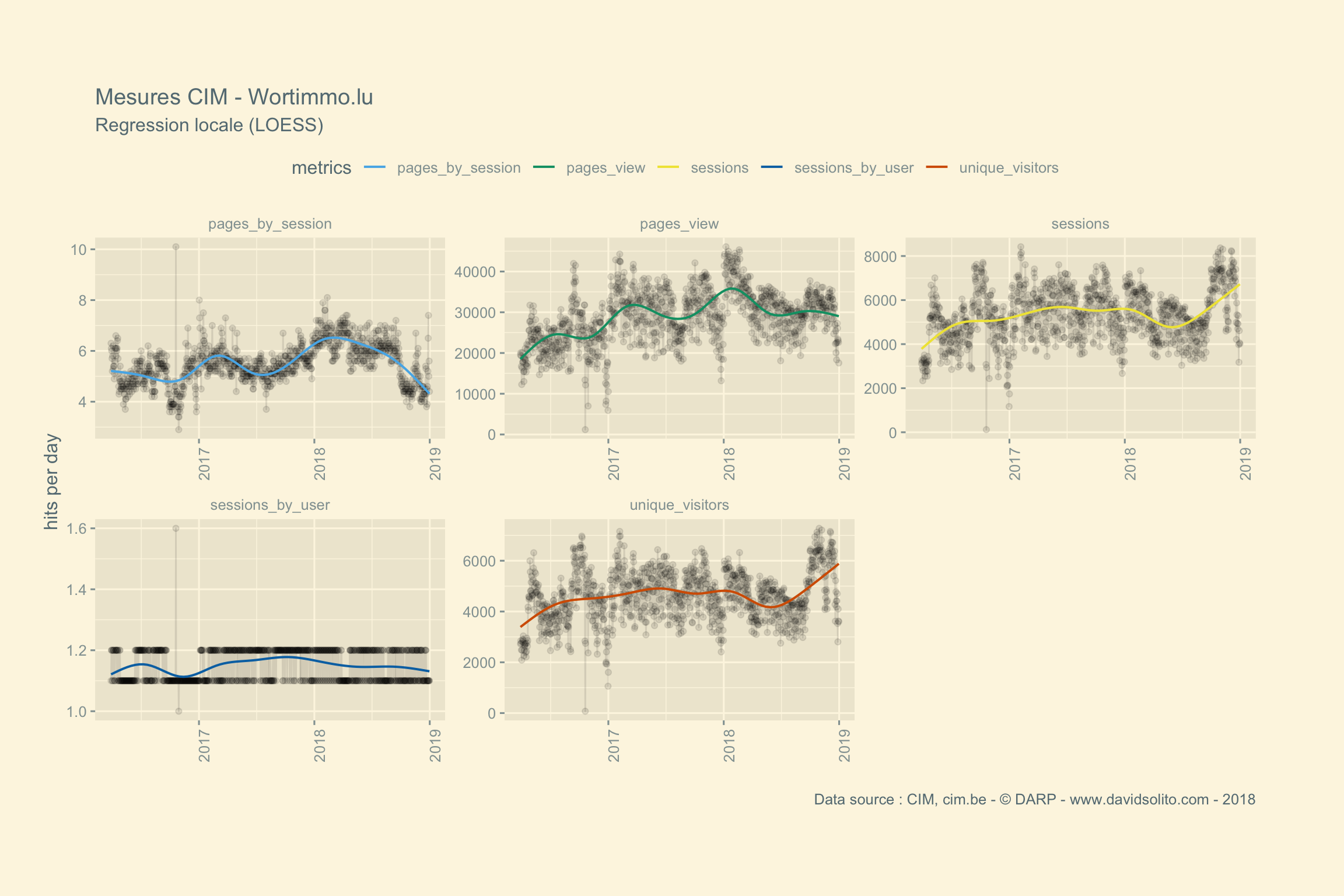
##
## [[19]]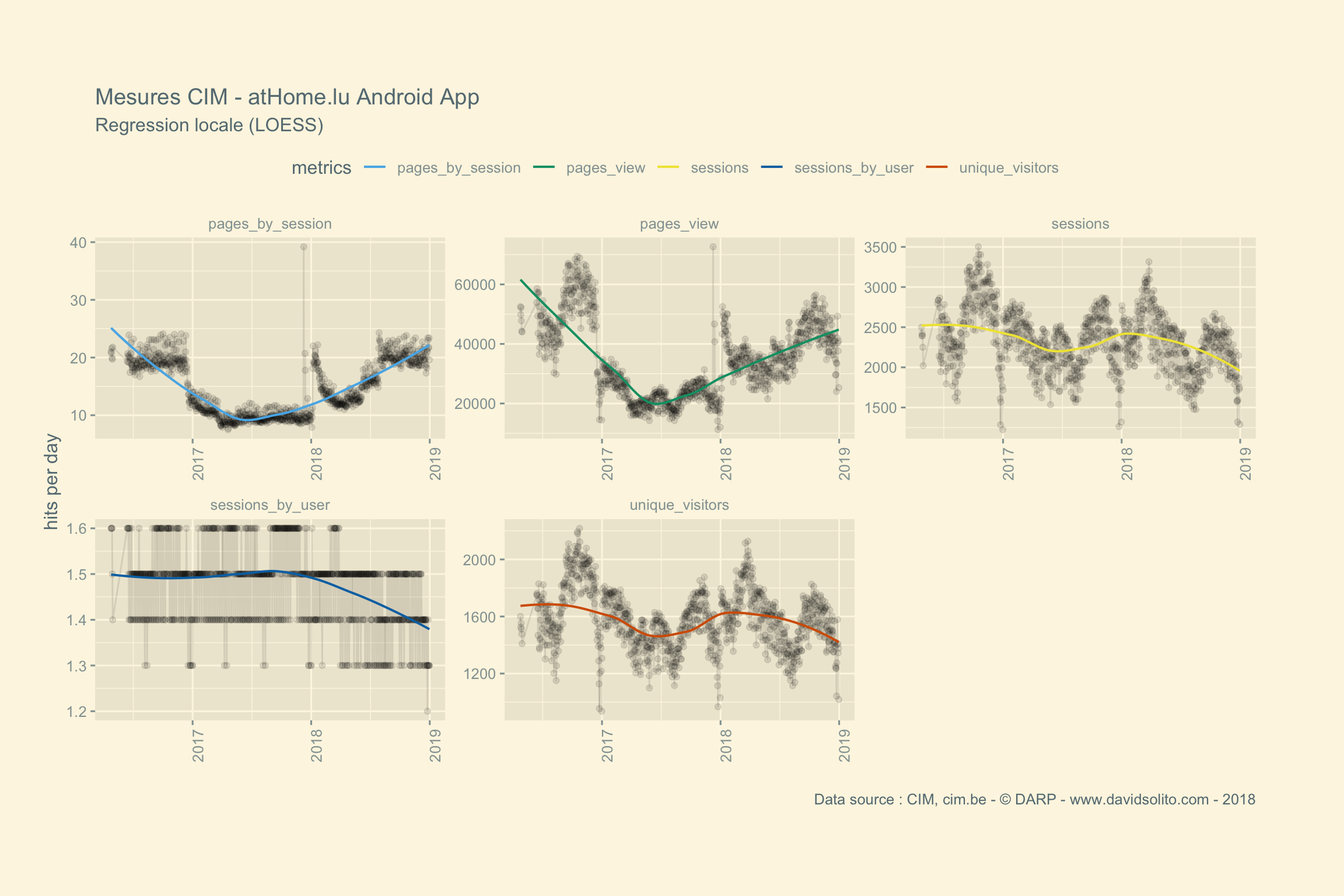
##
## [[20]]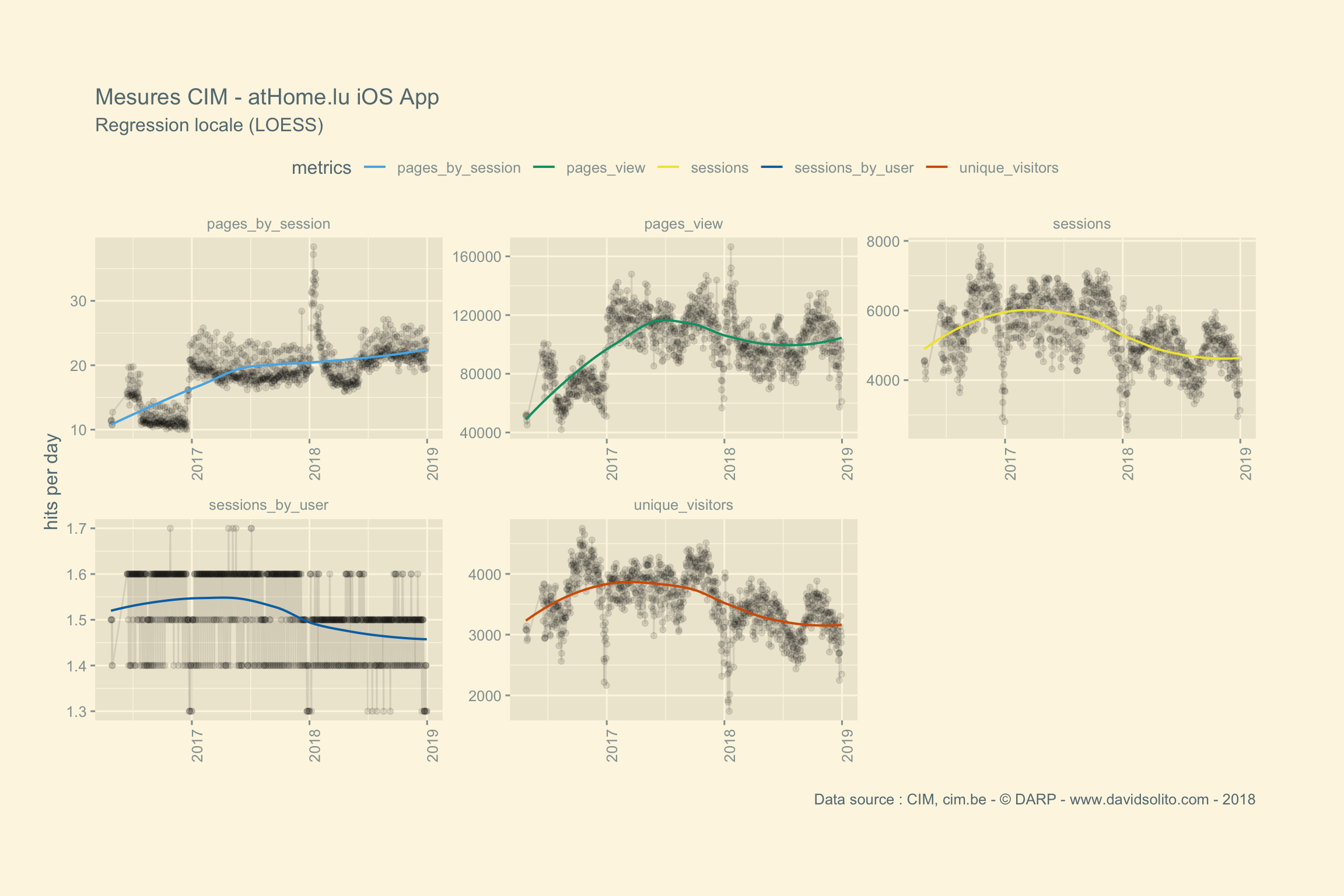
##
## [[21]]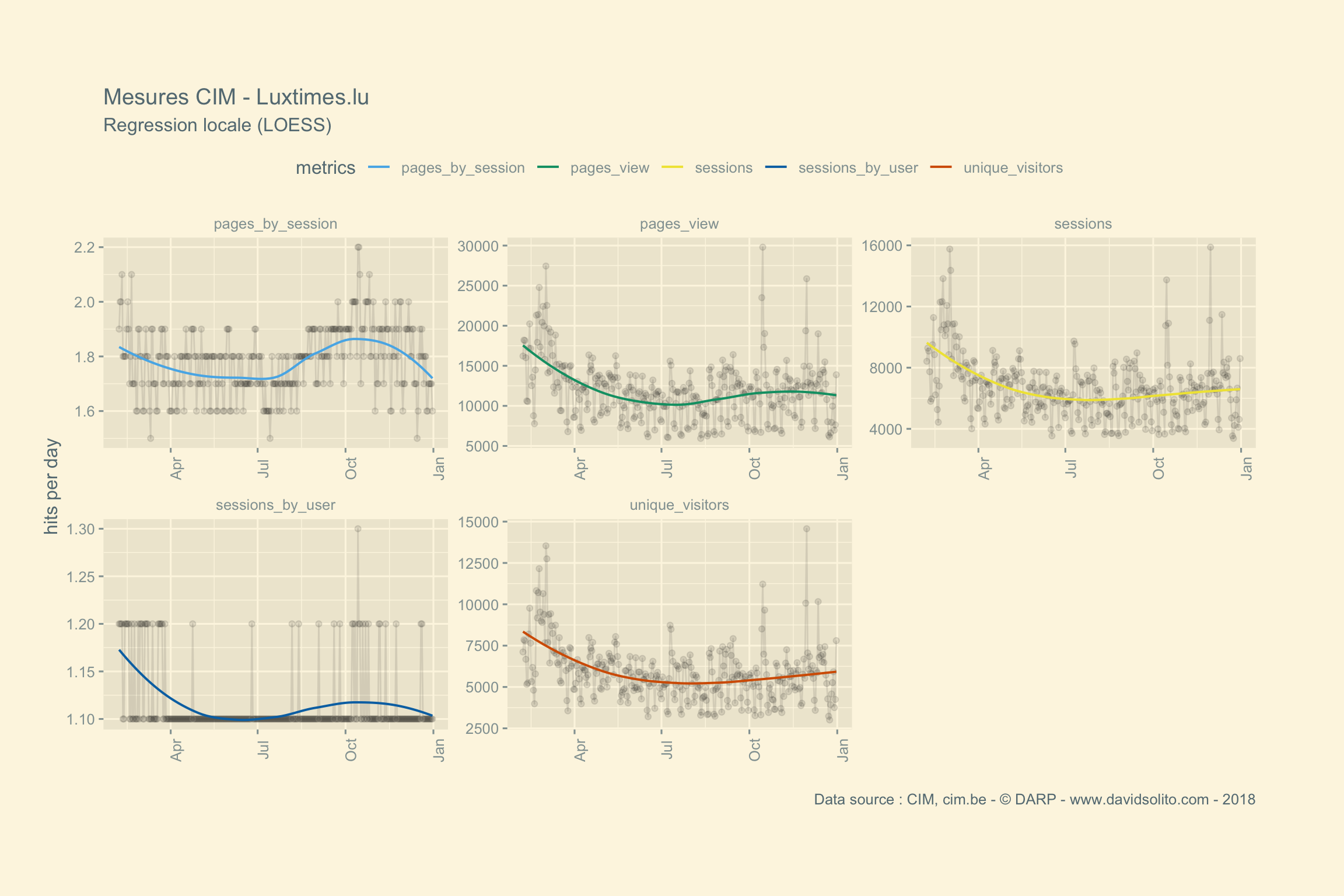
Heatmap des jours, des mois.
Il semble effectivement que le nombre de sessions soit plus élevé la semaine que le week-end. Est-ce le cas pour l’ensemble des publisheurs ? Regardonse cela d’un peu plus près. Nous avons à notre disposition le jour, le mois et l’année de la mesure. Grâce au package lubridate() nous pouvons créer une nouvelle variable pour les jours de la semaine, une pour le mois et une pour l’année. Super Easy.
cim3 <-
cim2 %>%
mutate(wday = lubridate::wday(date, label = TRUE)) %>% # 1 = dimanche, 7 = samedi
mutate(day = lubridate::day(date)) %>%
mutate(month = lubridate::month(date)) %>%
mutate(year = lubridate::year(date))
tail(cim3)## # A tibble: 6 x 10
## # Groups: date, site, type, category [2]
## date site type category metrics hits wday day month year
## <date> <chr> <chr> <chr> <chr> <dbl> <ord> <int> <dbl> <dbl>
## 1 2018-12-31 Wort.… Site News unique_… 4.41e4 Mon 31 12 2018
## 2 2018-12-31 Worti… Site Classifi… pages_b… 4.40e0 Mon 31 12 2018
## 3 2018-12-31 Worti… Site Classifi… pages_v… 1.76e4 Mon 31 12 2018
## 4 2018-12-31 Worti… Site Classifi… sessions 4.01e3 Mon 31 12 2018
## 5 2018-12-31 Worti… Site Classifi… session… 1.10e0 Mon 31 12 2018
## 6 2018-12-31 Worti… Site Classifi… unique_… 3.60e3 Mon 31 12 2018Nous allons calculer la moyenne des mesures selon le jour, le mois, l’année avec mutate() + mean().
cim4 <-
cim3 %>%
# filter(metrics == "sessions") %>%
# filter(site == "L'essentiel") %>%
group_by(site, metrics, year, month, wday) %>%
mutate(wday.mean = mean(hits)) %>%
ungroup() %>%
group_by(site, metrics, year, month) %>%
mutate(month.mean = mean(hits)) %>%
ungroup() %>%
group_by(site, metrics, year, month, day) %>%
mutate(day.hits = hits) %>% #ici je transforme la colonne hits en day.hit pour garder de la cohérence.
ungroup()
head(cim4)## # A tibble: 6 x 13
## date site type category metrics hits wday day month year
## <date> <chr> <chr> <chr> <chr> <dbl> <ord> <int> <dbl> <dbl>
## 1 2011-03-30 atHo… Site Classif… pages_… 3.44e+1 Wed 30 3 2011
## 2 2011-03-30 atHo… Site Classif… pages_… 2.57e+5 Wed 30 3 2011
## 3 2011-03-30 atHo… Site Classif… sessio… 7.48e+3 Wed 30 3 2011
## 4 2011-03-30 atHo… Site Classif… sessio… 8.00e-1 Wed 30 3 2011
## 5 2011-03-30 atHo… Site Classif… unique… 9.77e+3 Wed 30 3 2011
## 6 2011-03-30 atOf… Site Classif… pages_… 2.36e+1 Wed 30 3 2011
## # … with 3 more variables: wday.mean <dbl>, month.mean <dbl>,
## # day.hits <dbl>Nous y voilà. Réalisons les graphiques et amusons-nous.
Quel est le jour de la semaine qui en moyenne récolte le plus de sessions ?
cim4 %>%
filter(metrics == "sessions") %>%
filter(year == 2018) %>%
ggplot() +
aes(metrics, wday, group = metrics, fill = wday.mean ) +
geom_tile(col = "white", size = 0.5) +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text = element_text(size = 7)) +
scale_fill_viridis_c() +
coord_flip() +
labs(title = paste("Nombre de sessions"), subtitle = "Moyenne cumulée par jour de semaine", x = "", y = "2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(.~ site)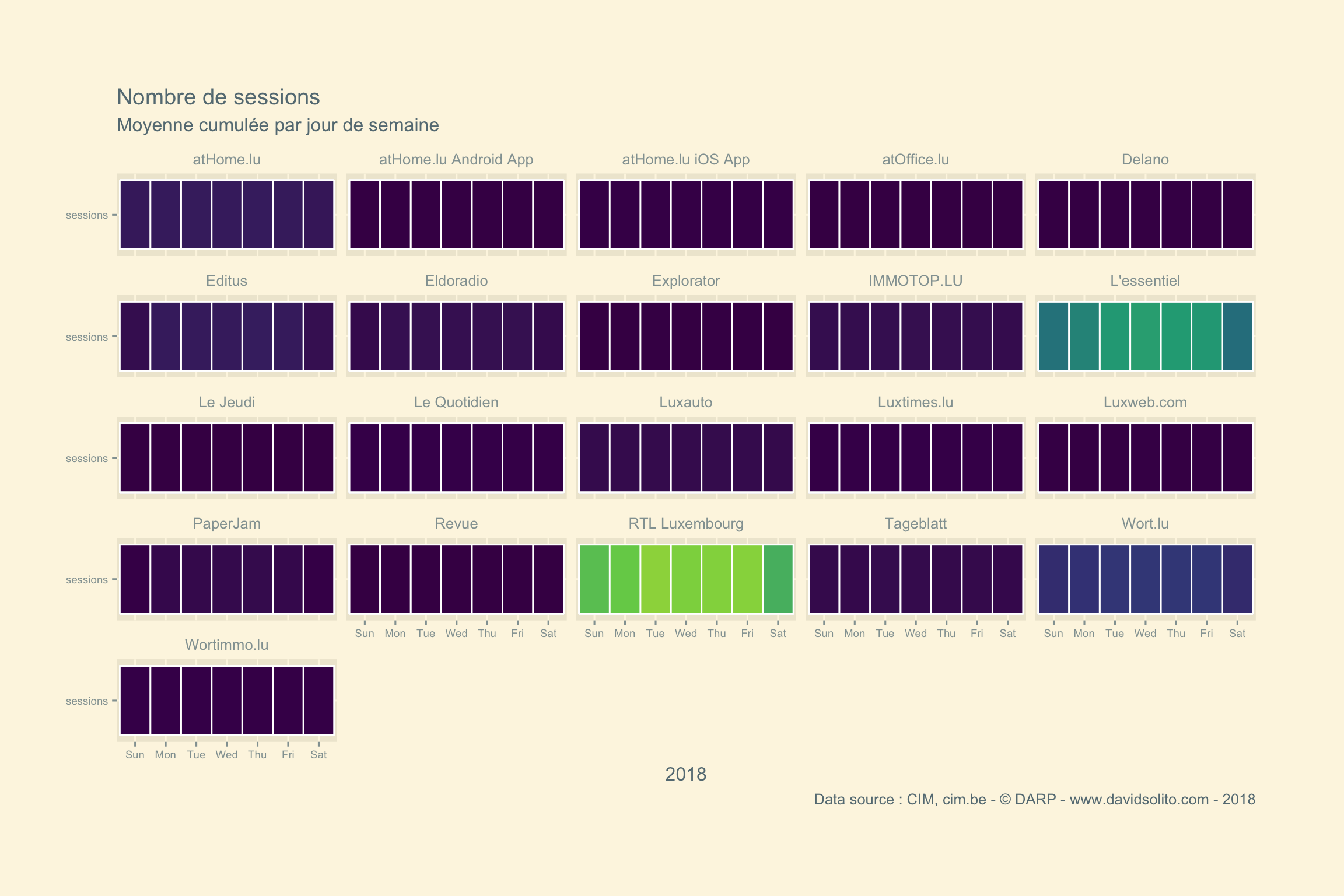
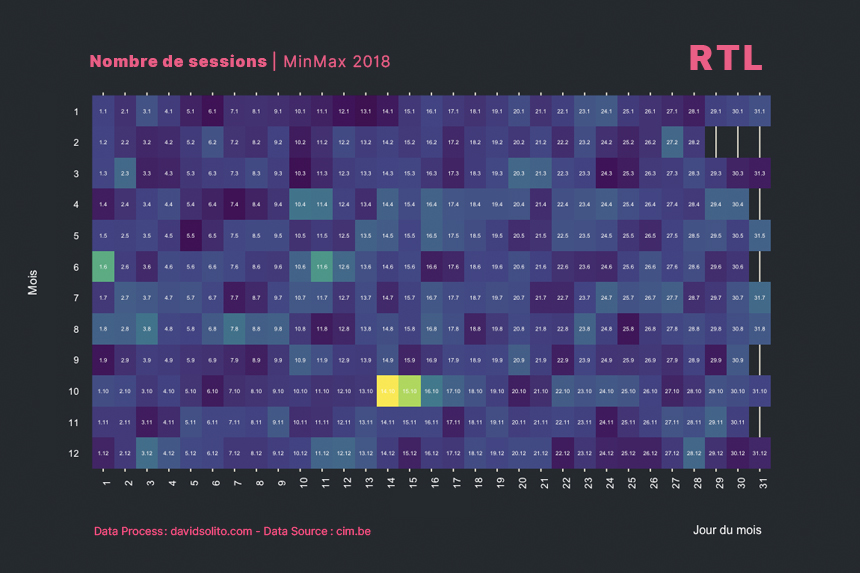
Nous voyons que l’échelle est graduée sur le résultat de l’ensemble des sites. Pour régler ce problème, je pense à une solution :
- Calculer une nouvelle colonne en normalisant les moyennes par normalisation des données : MinMax Scaling.
- Générer un graphique par site et rassembler l’ensemble avec
wrap_plots()du packagepatchwork.
Si vous avez une autre solution, n’hésitez à m’en faire part sur Twitter.
Attardons-nous sur la Solution 1.
cim4 %>%
filter(metrics == "sessions") %>%
# filter(site == "Le Jeudi") %>%
group_by(site, metrics, year, wday) %>%
summarise(wday.mean = mean(hits)) %>%
mutate(minmax = (wday.mean - min(wday.mean)) / (max(wday.mean)- min(wday.mean))) %>%
ggplot() +
aes(metrics, wday, fill = minmax ) +
geom_tile(col = "white", size = 0.5) +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text = element_text(size = 7)) +
scale_fill_viridis_c() +
coord_flip() +
labs(title = paste("Nombre de sessions"), subtitle = "MinMax de la moyenne par jour de la semaine", x = "", y = "Cumul 2011 - 2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(. ~ site)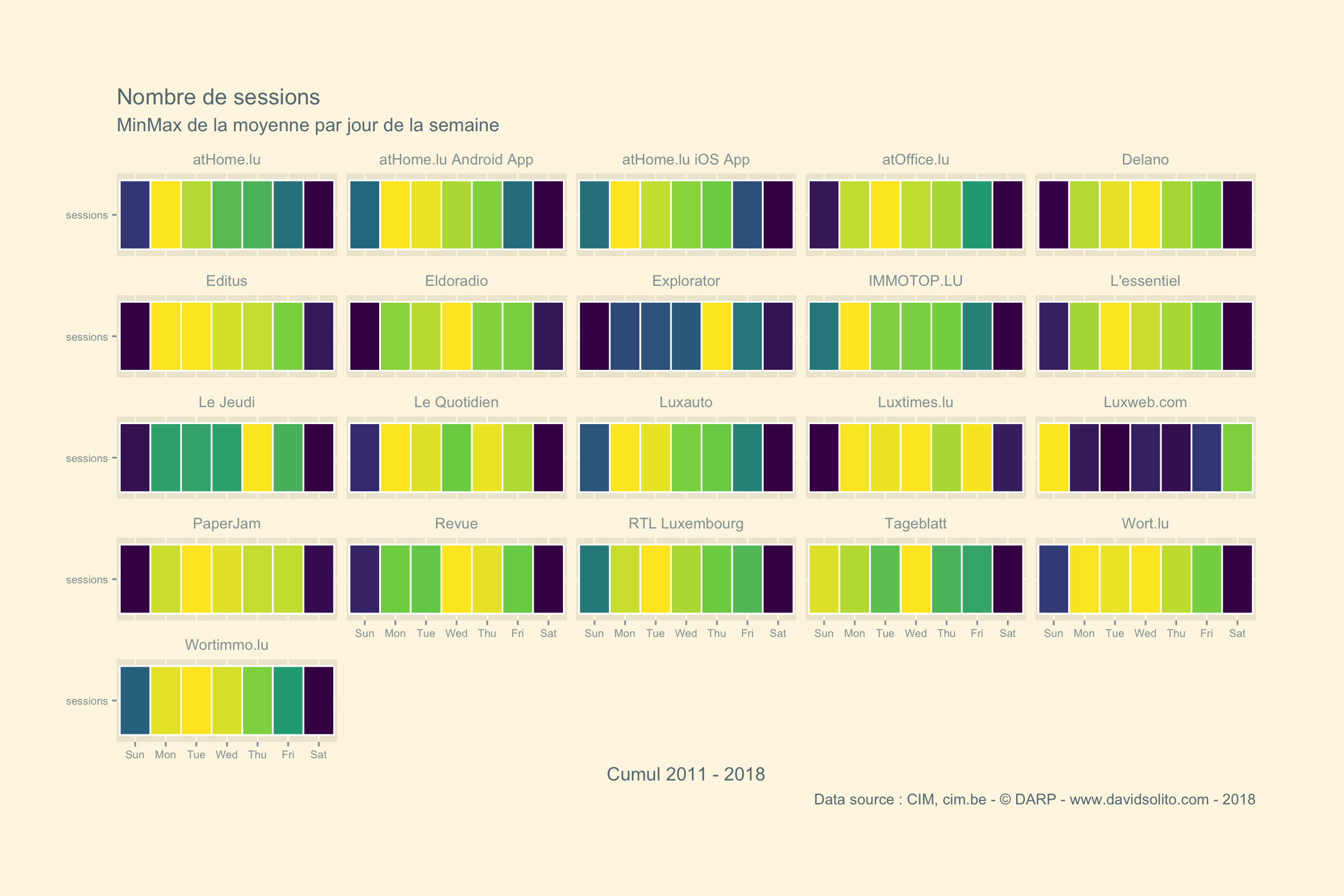
Beaucoup mieux! Nous obtenons là le cumul 2011 - 2018.
Quelle serait le résultat par année ?
cim4 %>%
filter(metrics == "sessions") %>%
# filter(site == "Le Jeudi") %>%
group_by(site, metrics, year, wday) %>%
summarise(wday.mean = mean(hits)) %>%
mutate(minmax = (wday.mean - min(wday.mean)) / (max(wday.mean)- min(wday.mean))) %>%
ggplot() +
aes(year, wday, fill = minmax ) +
geom_tile(col = "white", size = 0.25) +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text = element_text(size = 7)) +
scale_fill_viridis_c() +
coord_flip() +
labs(title = paste("Nombre de sessions"), subtitle = "MinMax de la moyenne cumulée par jour de la semaine", x = "", y = "2011 - 2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(. ~ site)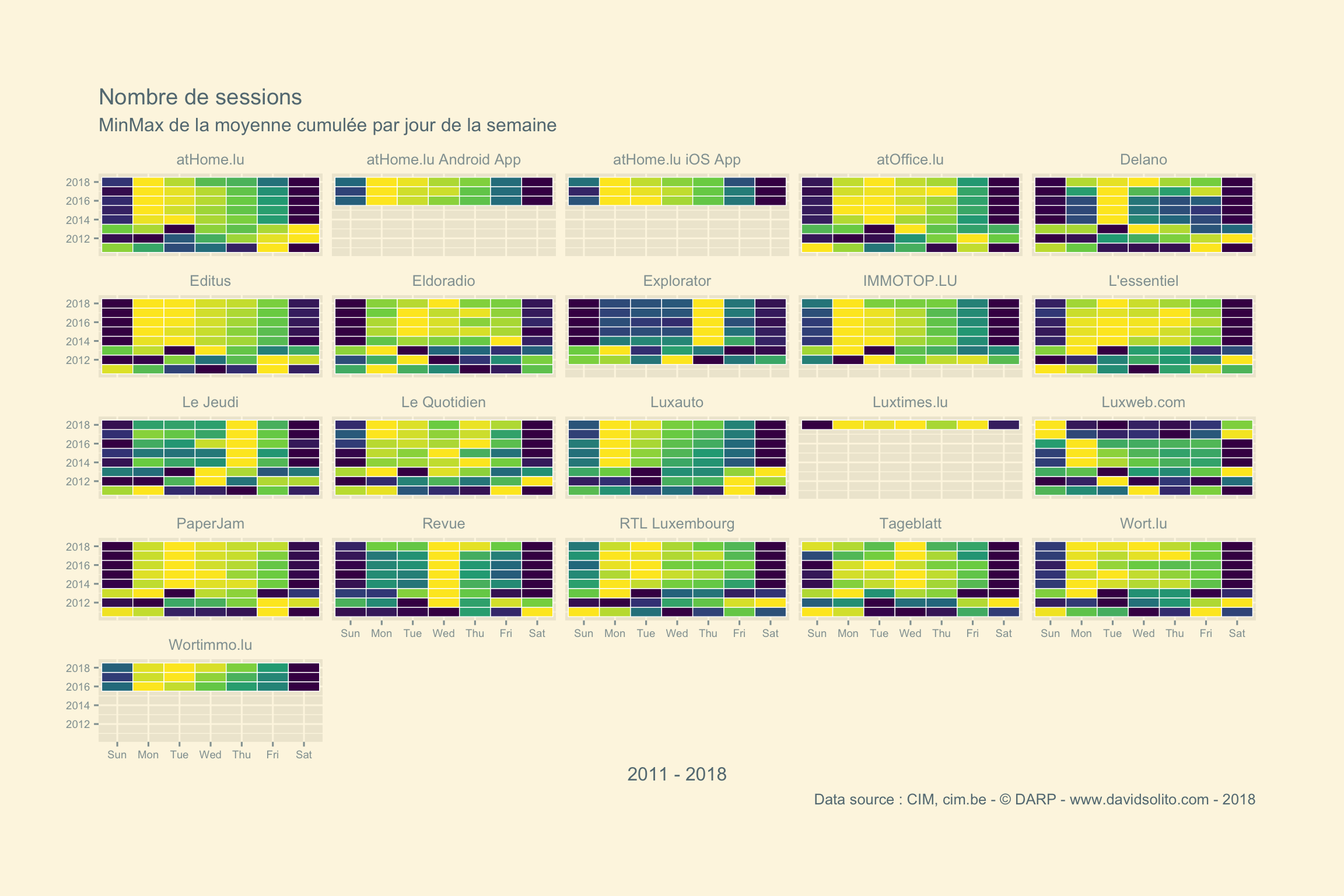
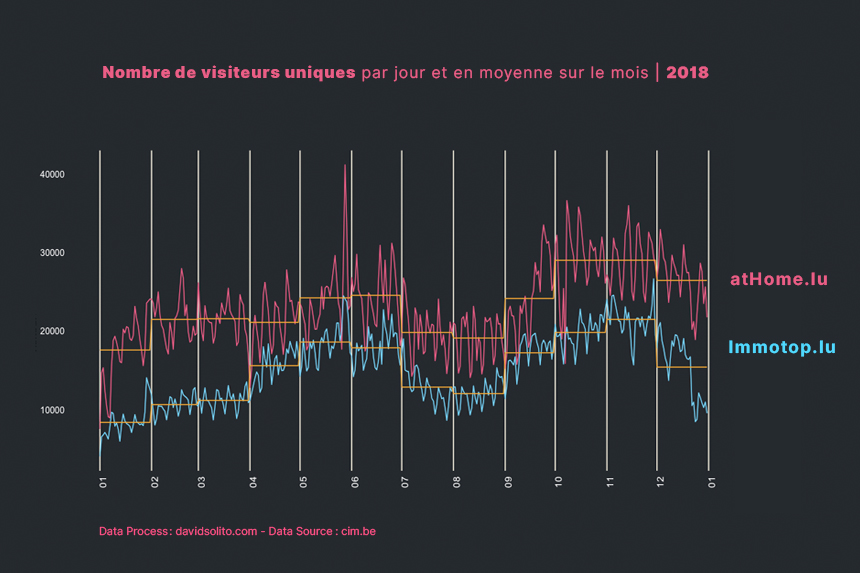
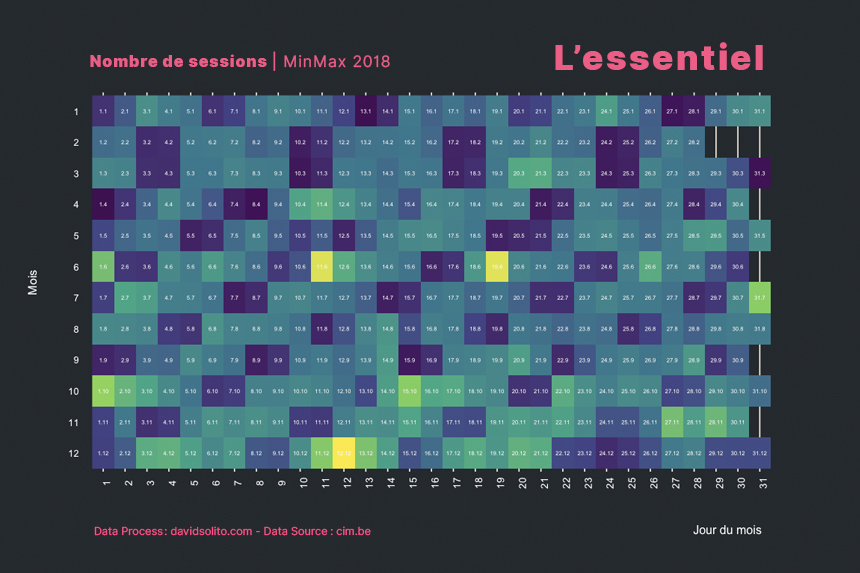
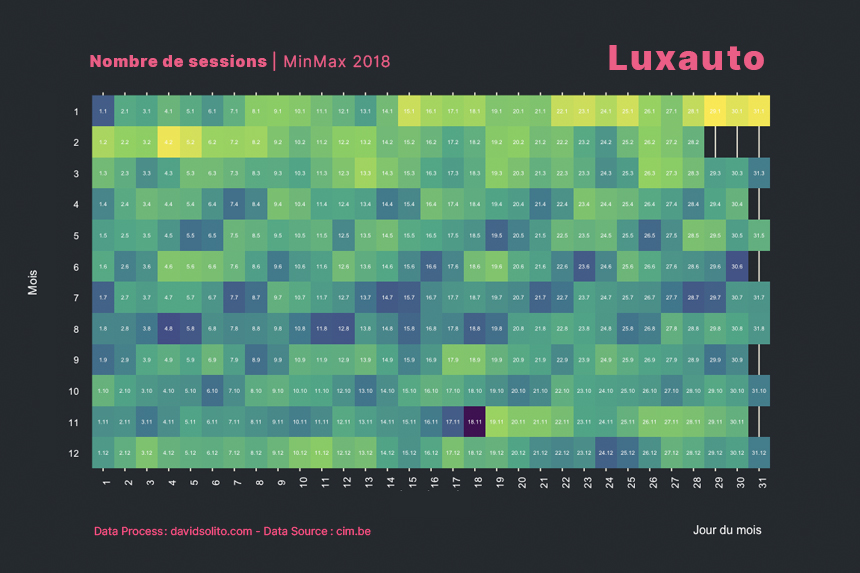
Quelles sont les jours en 2018 à obtenir le plus de sessions et par media ?
cim4 %>%
filter(metrics == "sessions") %>%
group_by(site, metrics, year) %>%
mutate(minmax = (hits- min(hits)) / (max(hits)- min(hits))) %>%
filter(year == 2018) %>%
ggplot() +
aes(day, forcats::fct_rev(factor(month)), fill = minmax ) +
geom_raster() +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text.y = element_text(size = 5)) +
scale_fill_viridis_c() +
scale_y_discrete() +
scale_x_continuous(breaks = seq(1,31, 5)) +
labs(title = paste("Nombre de sessions"), subtitle = "MinMax des sessions sur l'année 2018", x = "Jour du mois", y = "Mois", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(. ~ site)
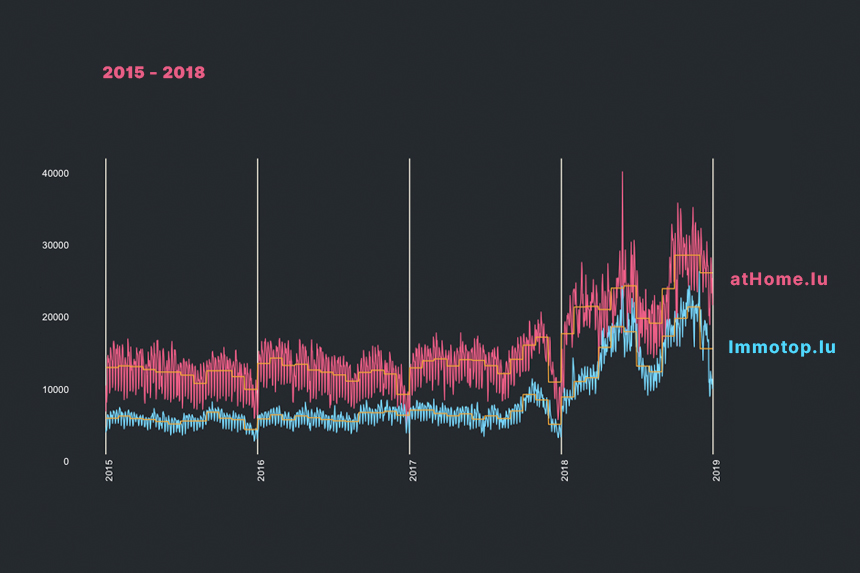
RTL Luxembourg - 2014 -> 2018 - Animation
Nous allons voir l’évolution de manière animée.
p <- cim4 %>%
filter(metrics == "sessions") %>%
filter(site %in% c("RTL Luxembourg", "L'essentiel")) %>%
group_by(site, metrics, year) %>%
mutate(minmax = (hits- min(hits)) / (max(hits)- min(hits))) %>%
filter(year >= 2014) %>%
ggplot() +
aes(day, forcats::fct_rev(factor(month)), fill = minmax ) +
geom_raster() +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text.y = element_text(size = 5)) +
scale_fill_viridis_c() +
scale_y_discrete() +
scale_x_continuous(breaks = seq(1,31, 5)) +
labs(title = paste("Nombre de sessions"), subtitle = "MinMax des sessions sur l'année {closest_state}", x = "Jour du mois", y = "Mois", caption = "© DARP - 2018") +
facet_wrap(. ~ site) +
gganimate::transition_states(year, 30, 4, wrap = TRUE) +
gganimate::ease_aes('sine-in-out')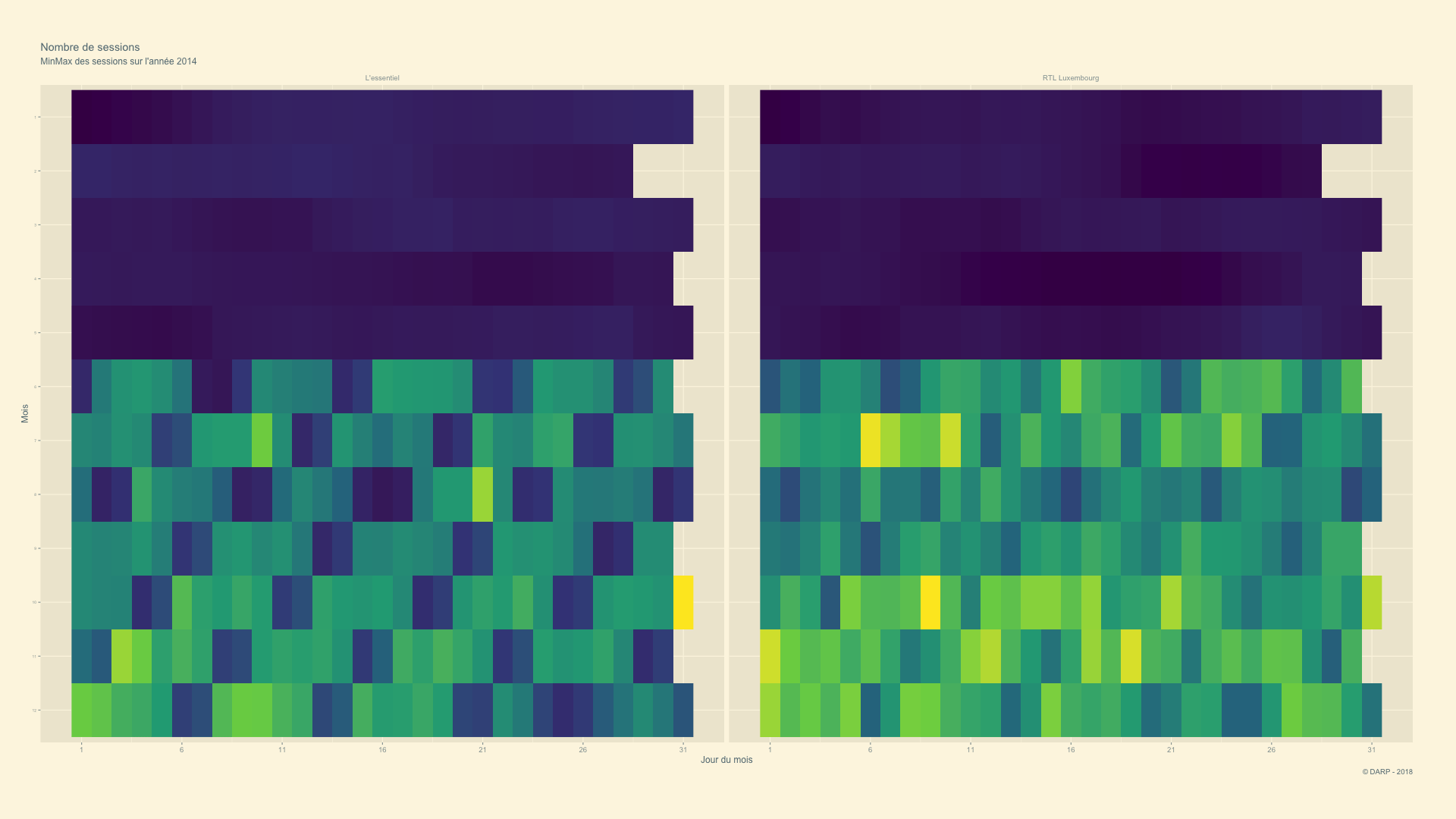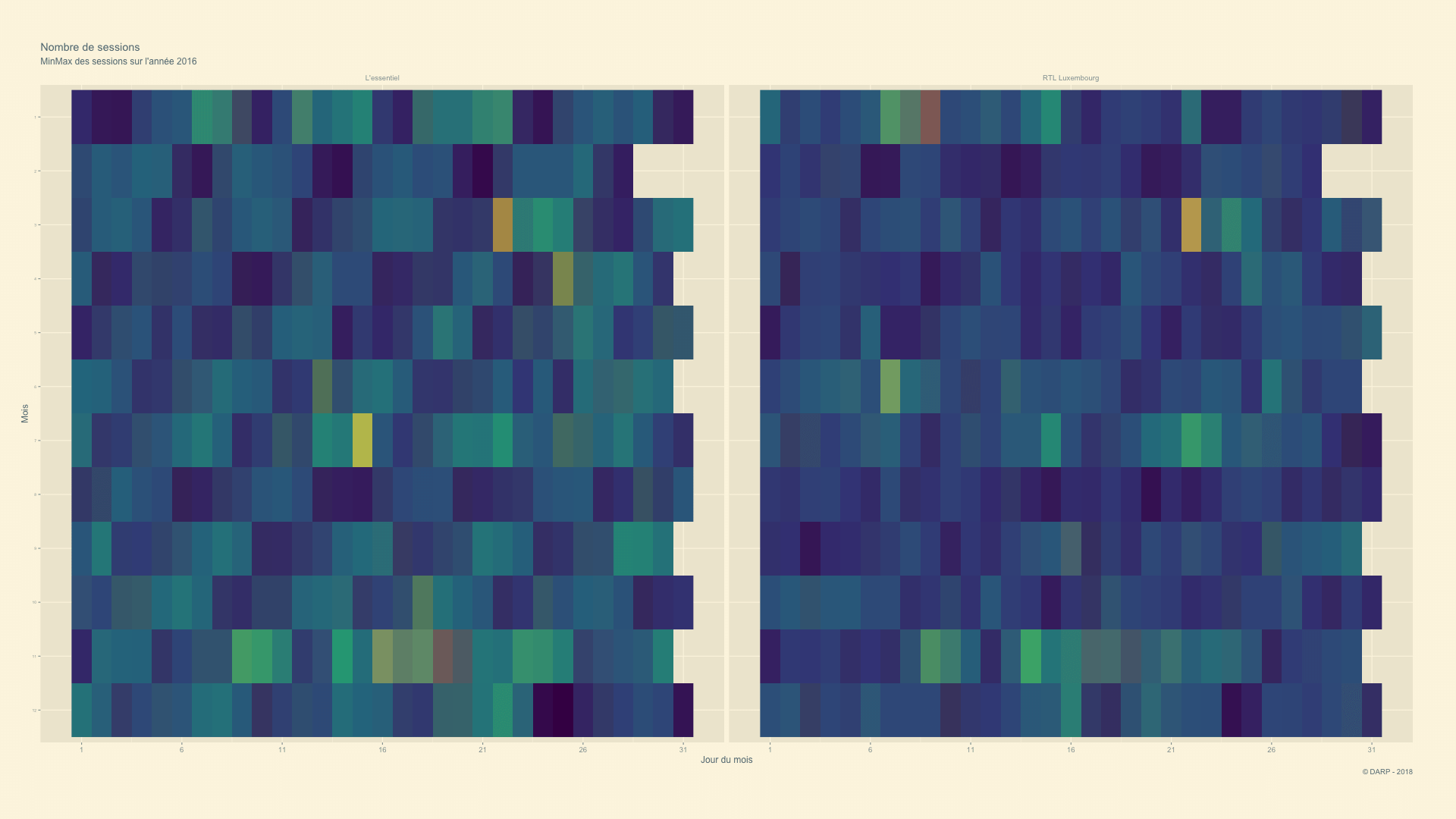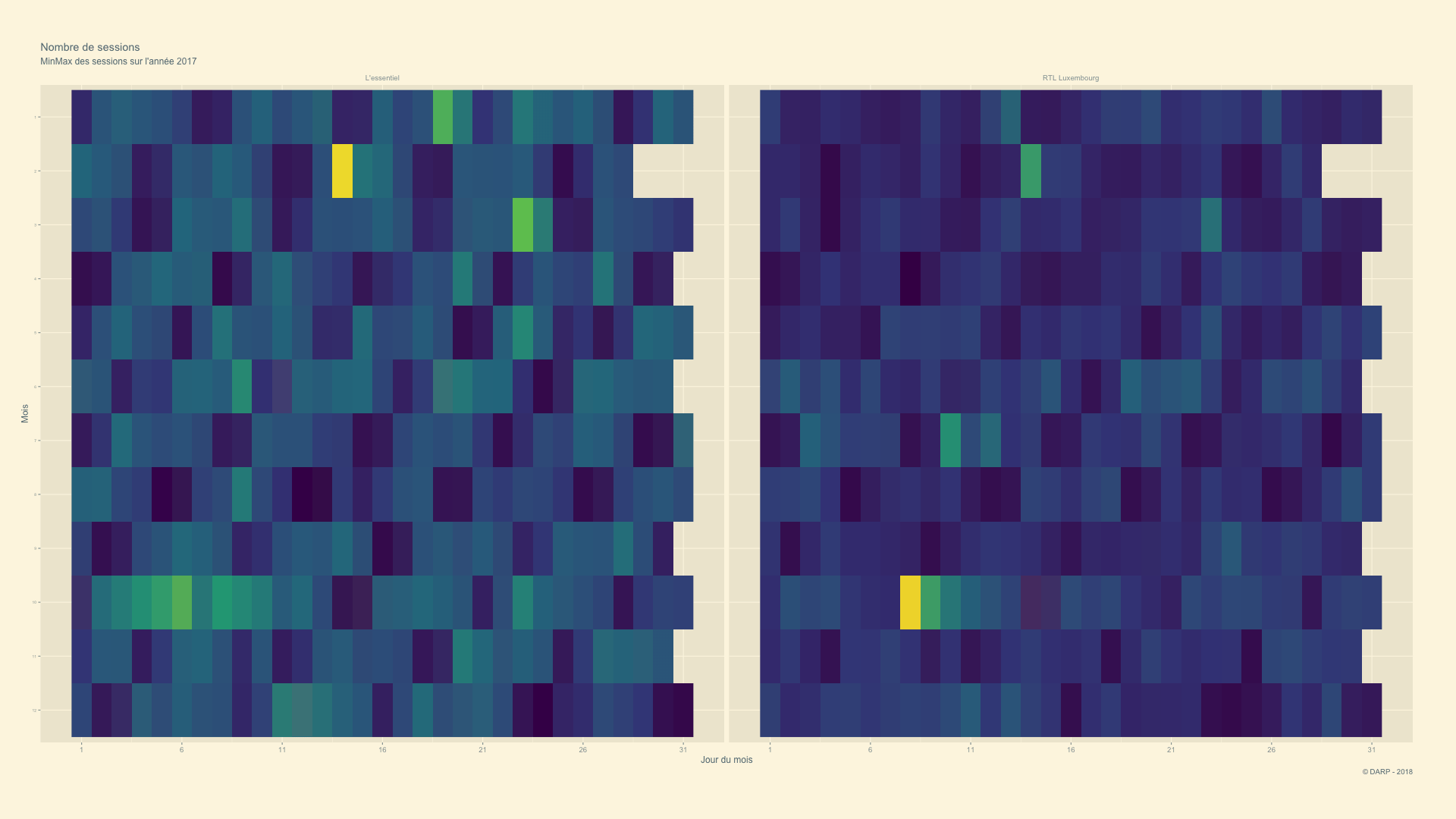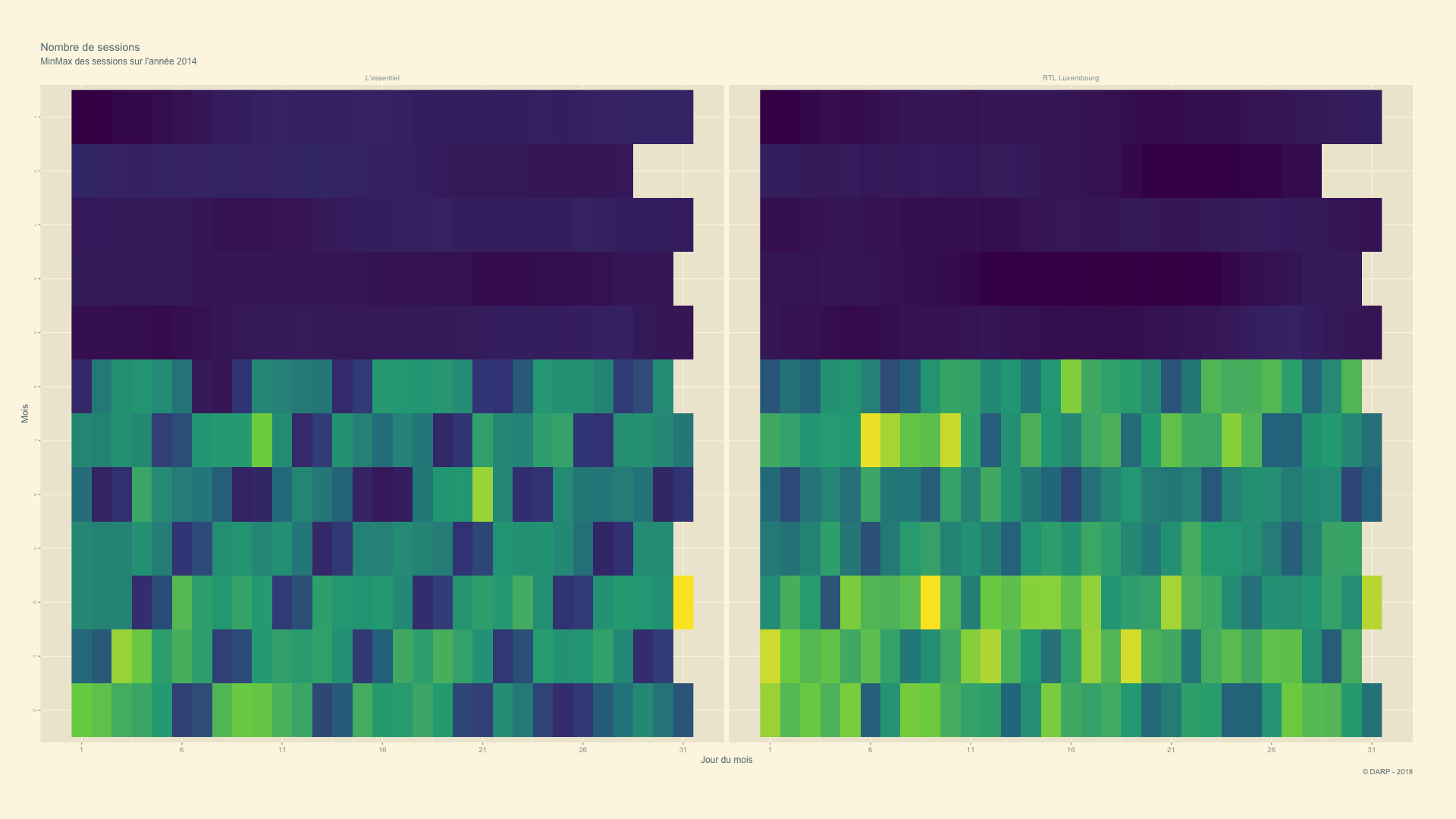
Adaptons le graphique cette fois avec l’ensemble des metrics sur 2018.
cim4 %>%
# filter(metrics %in% c("sessions", "pages_view")) %>%
# filter(site == "Le Jeudi") %>%
group_by(site, metrics, year, wday) %>%
summarise(wday.mean = mean(hits)) %>%
mutate(minmax = (wday.mean - min(wday.mean)) / (max(wday.mean)- min(wday.mean))) %>%
filter(year == 2018) %>%
ggplot() +
aes(metrics, wday, fill = minmax ) +
geom_tile(col = "white", size = 0.25) +
ggthemes::theme_solarized_2() +
theme(legend.position = "none", plot.margin = unit(c(2,2,2,1), "cm"), axis.text = element_text(size = 7)) +
scale_fill_viridis_c() +
coord_flip() +
labs(title = paste("Performance par Metrics"), subtitle = "MinMax de la moyenne 2018 par jour de la semaine", x = "", y = "2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(. ~ site)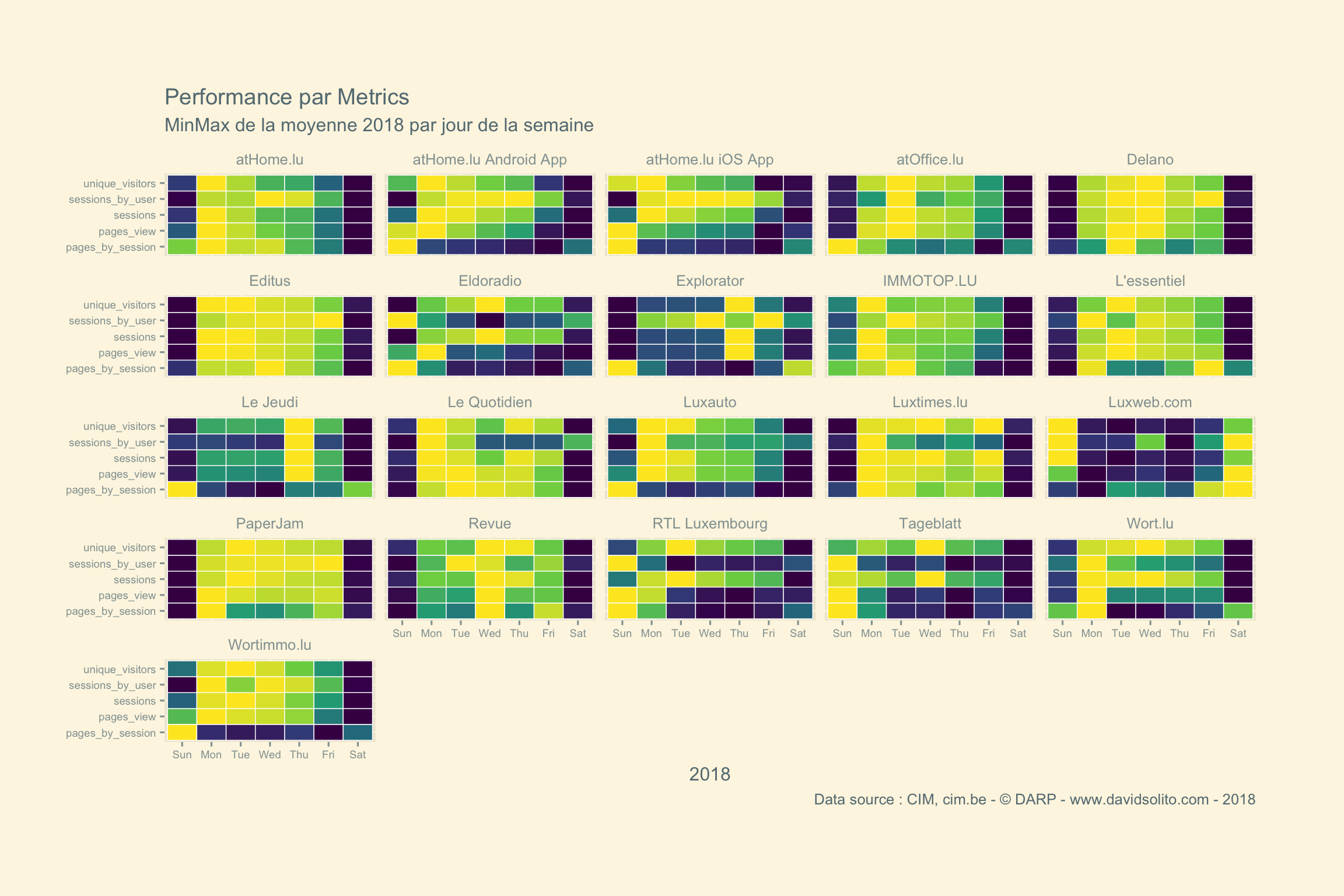
Y a-t-il une corrélation systématique entre le nombre de sessions et le nombre de pages vues?
cim4 %>%
filter(metrics %in% c("sessions", "pages_view")) %>%
# filter(site == "Le Jeudi") %>%
group_by(site, metrics, year, wday) %>%
summarise(wday.mean = mean(hits)) %>%
mutate(minmax = (wday.mean - min(wday.mean)) / (max(wday.mean)- min(wday.mean))) %>%
filter(year == 2018) %>%
ggplot() +
aes(wday, minmax, group = metrics) +
# geom_area(aes(fill = metrics), position = "dodge", alpha = 0.7) +
geom_line(aes(col = metrics), alpha = 0.8, size = 1) +
geom_point(aes(col = metrics), alpha = 0.7) +
scale_y_continuous(breaks = c(0,1), labels = c("min", "max")) +
scale_color_fivethirtyeight() +
ggthemes::theme_solarized_2() +
theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm"), axis.text = element_text(size = 7)) +
labs(title = paste("Pages vues vs Sessions"), subtitle = "MinMax de la moyenne par jour de la semaine en 2018", x = "", y = "", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(. ~ site)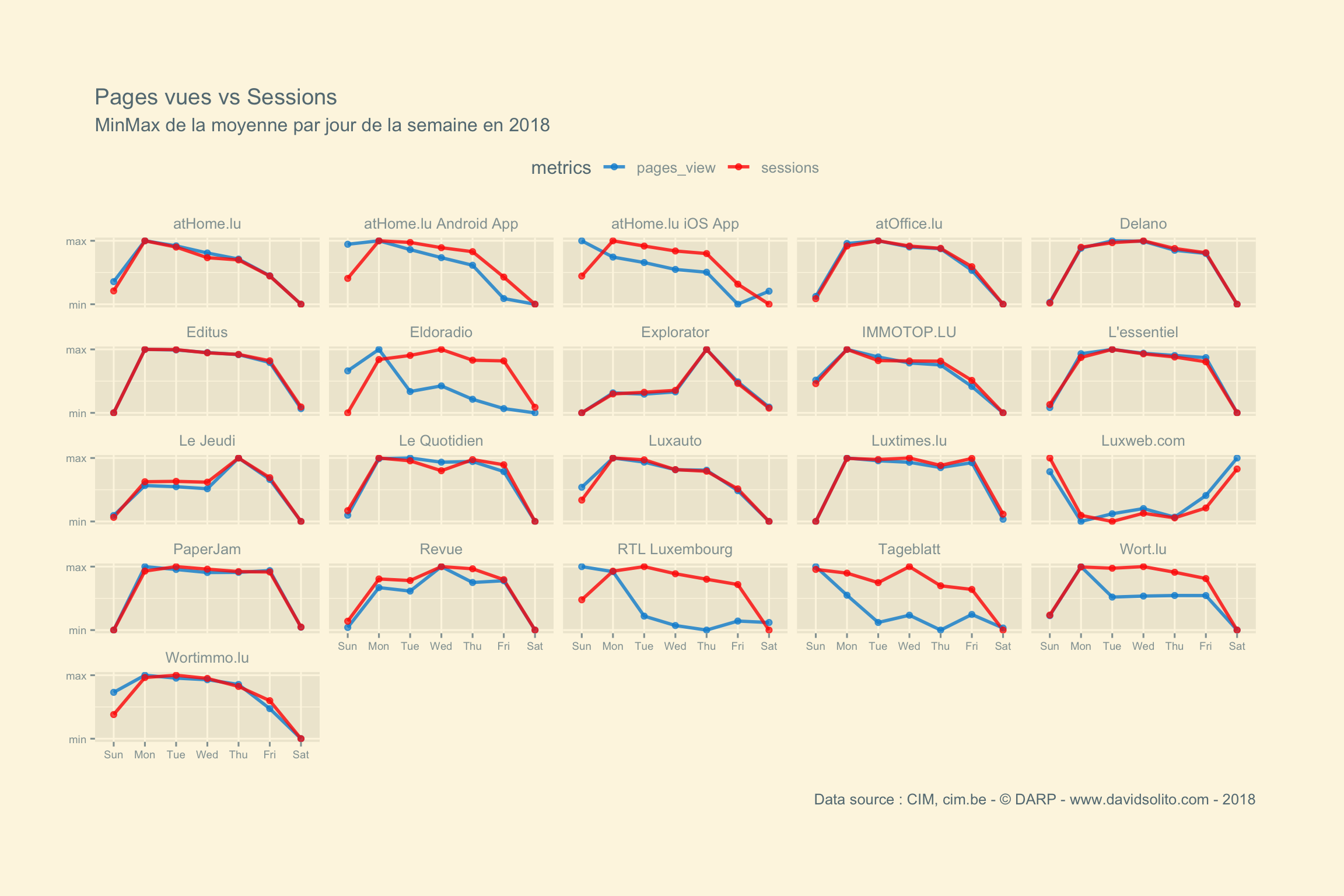
Certains media comme RTL Luxembourg enregistrent moins de sessions le dimanche, mais ont un engagement plus élevé. Comprenez par là que le nombre de pages consultées lors d’une session est plus grand. Soit plus de pages consultées par moins d’utilisateurs le week-end. Nous observons ce phénomène plus marqué sur le site Eldoradio. L’Essentiel, 2e support avec le plus d’audience voit son nombre de pages consultées évoluer de manière corrélée avec le nombre de sessions.
Est-ce que ce constat est spécifique à 2018 ?
cim4 %>%
filter(metrics %in% c("sessions", "pages_view")) %>%
filter(site %in% c("L'essentiel", "RTL Luxembourg", "Eldoradio", "Tageblatt")) %>%
group_by(site, metrics, year, wday) %>%
summarise(wday.mean = mean(hits)) %>%
mutate(minmax = (wday.mean - min(wday.mean)) / (max(wday.mean)- min(wday.mean))) %>%
filter(year >= 2015) %>%
ggplot() +
aes(wday, minmax, group = metrics) +
# geom_area(aes(fill = metrics), position = "dodge", alpha = 0.7) +
geom_line(aes(col = metrics), alpha = 0.8, size = 1.5) +
geom_point(aes(col = metrics), alpha = 0.8, size = 3) +
scale_y_continuous(breaks = c(0,1), labels = c("min", "max")) +
scale_color_fivethirtyeight() +
ggthemes::theme_solarized_2() +
theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm")) +
labs(title = paste("Sessions vs Pages Views"), subtitle = "MinMax des moyennes par jour de la semaine", x = "", y = "2015 - 2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_wrap(site ~ year, ncol = 4)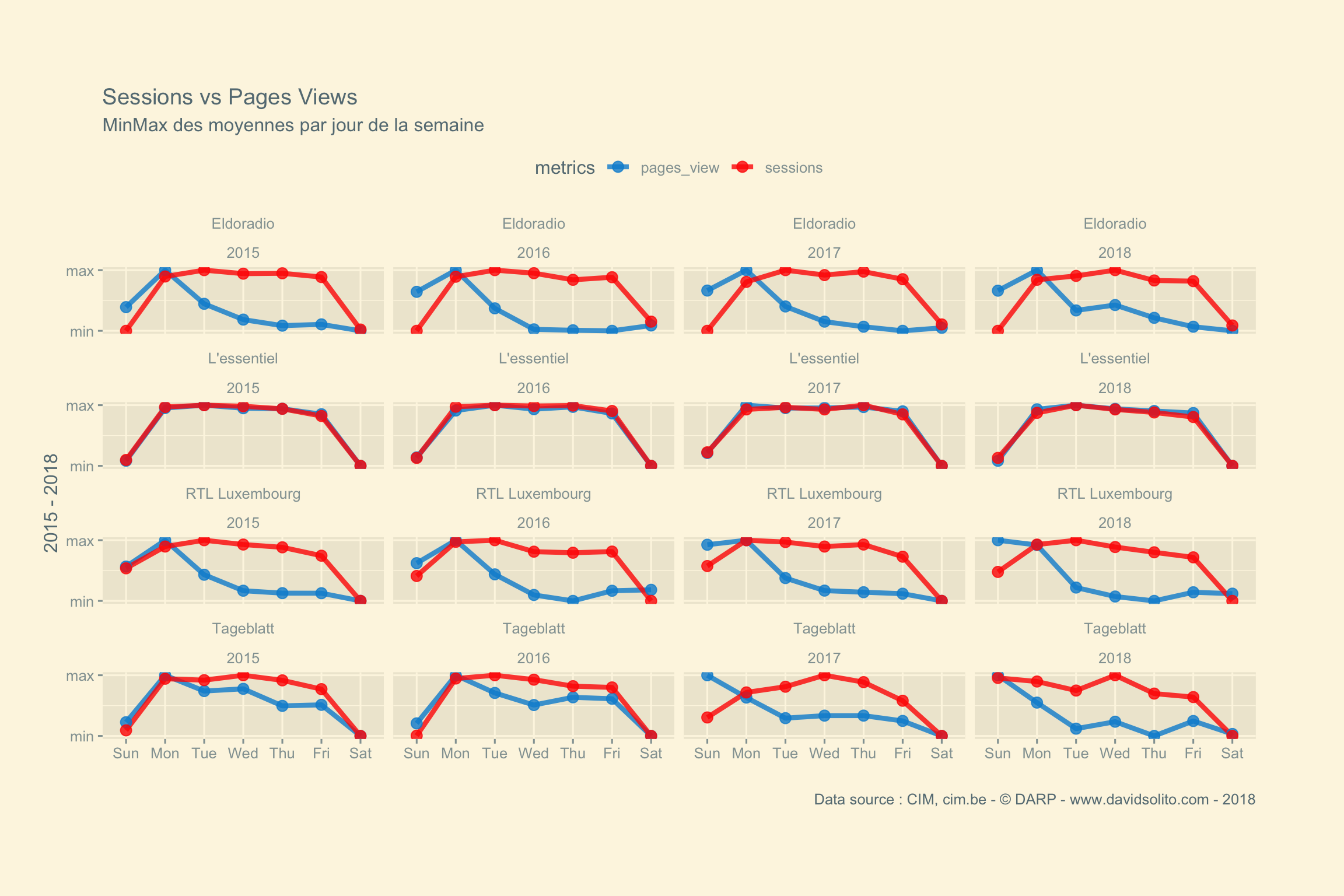
Nous pouvons observer le même phénomène d’année en année. Une autre façon de représenter cela serait de montrer le résultat du week-end versus l’ensemble de la semaine. Nous nous concentrons dès lors plus sur le sens du graphique. Moins d’encre, plus de reflexion :-) Vous pouvez consulter cet excellent poste d’Avinash Kauhshik : It’s Not The Ink, It’s The Think: 6 Effective Data Visualization Strategies
cim4 %>%
filter(metrics %in% c("sessions", "pages_view")) %>%
filter(site %in% c("L'essentiel", "RTL Luxembourg", "Eldoradio", "Tageblatt")) %>%
mutate(label = case_when(wday %in% c("Sat", "Sun") ~ "Weekend")) %>%
mutate(label = ifelse(is.na(label), "Week", "Weekend")) %>%
group_by(site, metrics, year, label) %>%
summarise(label.mean = mean(hits)) %>%
mutate(minmax = (label.mean - min(label.mean)) / (max(label.mean)- min(label.mean))) %>%
mutate(base100 = (label.mean/first(label.mean)) * 100) %>%
mutate(t = base100 - 100) %>%
filter(year >= 2018) %>%
select(site, metrics, year, label, t) %>%
ggplot() +
aes(label, t, fill = metrics ) +
geom_col(position = "dodge") +
scale_fill_fivethirtyeight() +
ggthemes::theme_solarized_2() +
geom_hline(yintercept = 0, size = 0.5, col = "black") +
geom_label(aes(label = paste0(round(t, 1), "%")), position = position_dodge2(width = .9), size = 3, fill = "black", col = "white") +
scale_y_continuous(limits = c(-50, 50), breaks = seq(-50, 50, 10), labels = scales::percent(seq(-0.5, 0.5, 0.1))) +
theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm")) +
labs(title = paste("Sessions & Pages Views - Weekend Vs Week"), subtitle = "Taux d'évolution moyen en 2018", x = "", y = "2018", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_grid(year ~ site)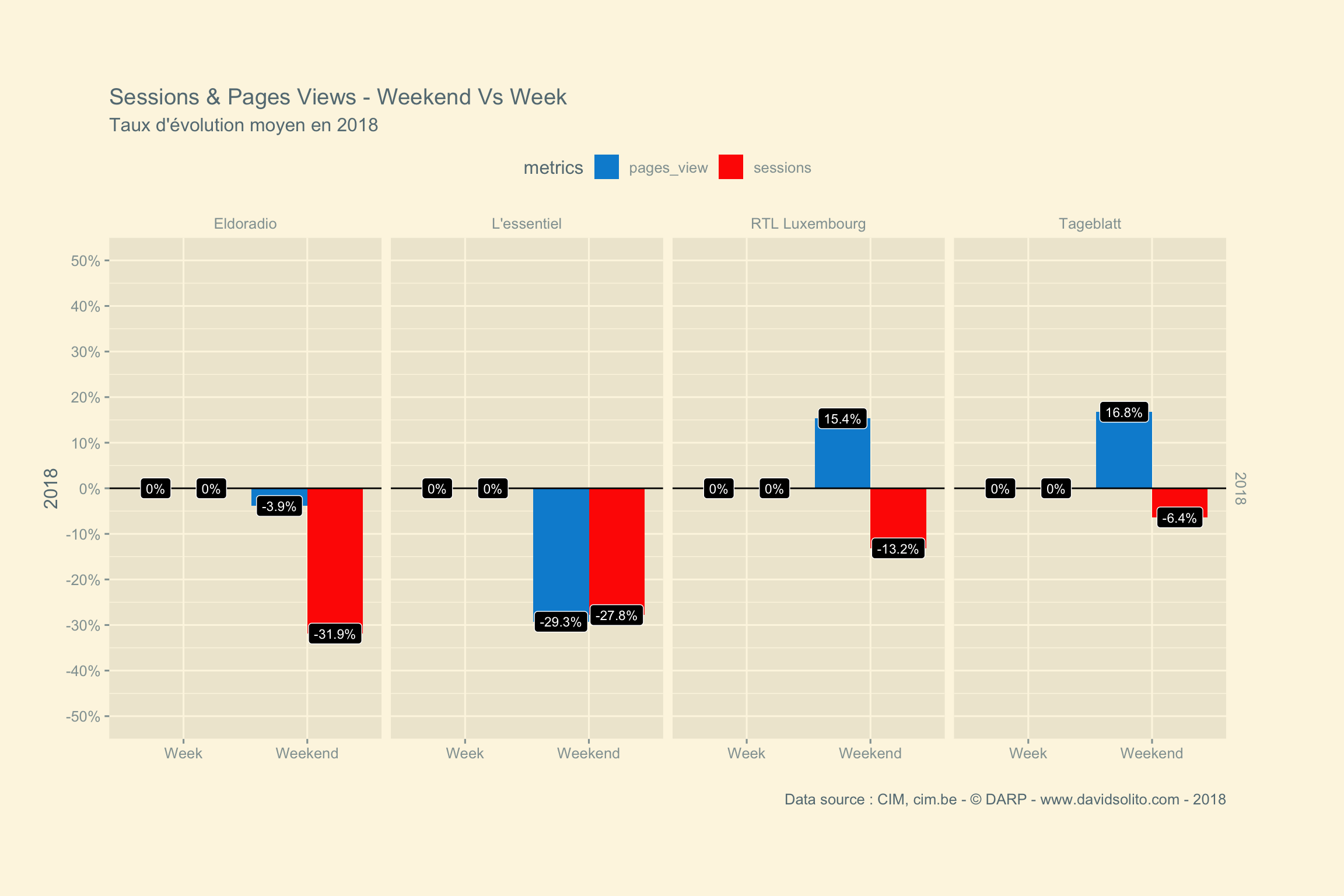
Nous voyons bien les différences entre la semaine et le weekend.
Le nombre de pages vues cumulées sur les sites d’informations
Nous allons pour clôturer cette première partie sur l’exploration des mesures du CIM, calculer le cumul du nombre de pages vues depuis juillet 2014. (les données avant cette date sont d’une autre nature comme nous l’avons vu plus haut). Nous allons créer un vecteur avec le total du cumul pour les 5 premiers.
cim4 %>%
select(1:6) %>%
filter(date >= "2014-07-01") %>%
filter(category == "News") %>%
filter(metrics == "pages_view") %>%
group_by(site, metrics) %>%
mutate(cum_sum = cumsum(hits)) %>%
group_by(site) %>%
summarize(max = max(cum_sum)) %>%
top_n(5, max) %>%
pull(max) -> d_endscim4 %>%
select(1:6) %>%
filter(date >= "2014-07-01") %>%
filter(category == "News") %>%
filter(metrics == "pages_view") %>%
group_by(site, metrics) %>%
mutate(cum_sum = cumsum(hits)) %>%
ggplot() +
aes(date, cum_sum, group = site) +
geom_line(aes(col = site), size = 0.6) +
ggthemes::theme_solarized_2() +
scale_color_economist() +
scale_y_continuous(sec.axis = sec_axis(~ ., breaks = d_ends, labels = scales::number(d_ends))) +
scale_x_date(limits = c(as.Date("2014-07-01"), as.Date("2018-12-31")), expand = c(0,0)) +
theme(axis.text.y.left = element_blank(), legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm"), axis.ticks = element_blank()) +
labs(title = paste("Cumul des pages vues"), subtitle = "Du 01.07.2014 au 31.12.2018", x = "Années", y = "Pages vues", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018")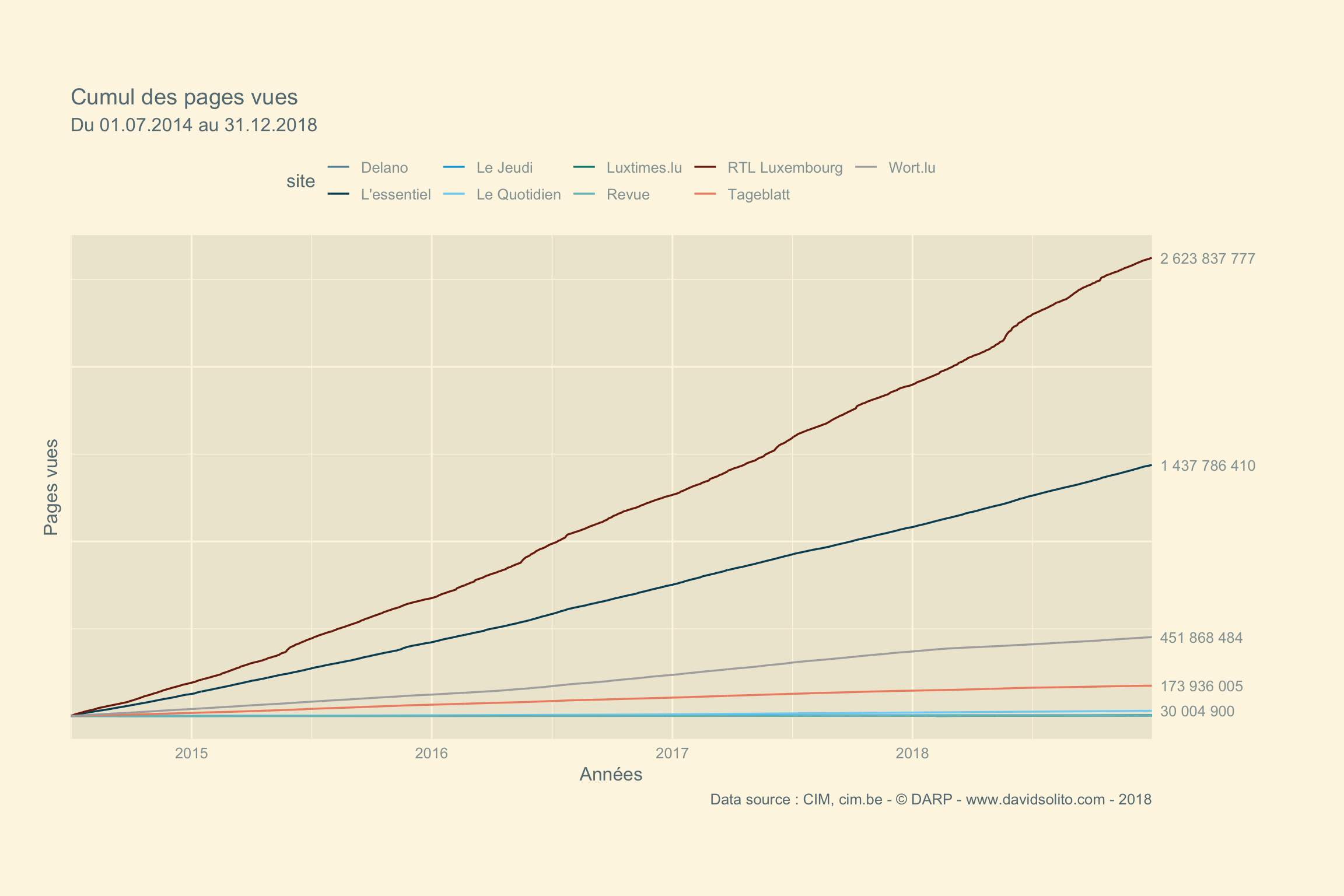
One more thing. Est-ce que ce nombre est en progression d’année en année ?
Calculons l’indice base 100. L’indice base 100 est bien pratique. On ramène l’évolution à un départ de 100 et tout le reste sera rapporté à cette valeur. C’est le même principe que les pourcentages : on rapporte des nombres à une valeur de 100. Si vous comprenez l’utilité d’un pourcentage, vous comprenez l’utilité d’une base 100 : c’est comme un pourcentage qui évolue dans le temps.
\(\large base100 = \frac {Valeur2} {Valeur1} * 100\)
Une fois cela calculé nous pouvons sortir le taux d’évolution facilement. Ainsi chaque valeur indice 100 indique le taux d’évolution par rapport à la valeur de départ. Il est donc facile de passer de la base 100 au taux d’évolution et inversement.
\(\Large t = \frac {base100 - 100} {100}\)
cim4 %>%
select(1:10) %>%
filter(date >= "2015-01-01") %>%
filter(category == "News") %>%
filter(metrics == "pages_view") %>%
group_by(site, year) %>%
mutate(cum_sum = cumsum(hits)) %>%
summarise(sum_page = max(cum_sum)) %>%
mutate(base100 = (sum_page/first(sum_page)) * 100) %>%
mutate(t = (base100 - 100)/100) %>%
mutate(t = scales::percent(t))## # A tibble: 33 x 5
## # Groups: site [9]
## site year sum_page base100 t
## <chr> <dbl> <dbl> <dbl> <chr>
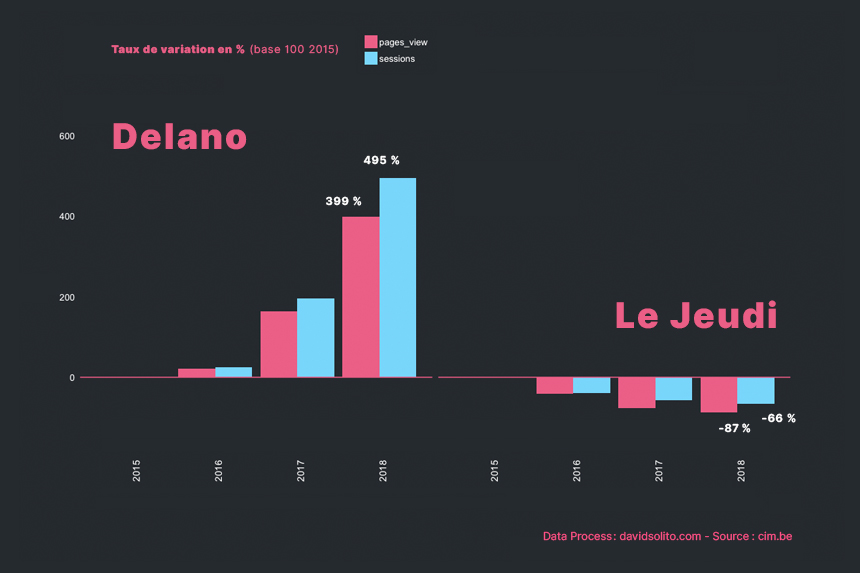
## 1 Delano 2015 229918 100 0%
## 2 Delano 2016 277461 121. 21%
## 3 Delano 2017 604518 263. 163%
## 4 Delano 2018 1148731 500. 400%
## 5 L'essentiel 2015 295497182 100 0.0%
## 6 L'essentiel 2016 329067304 111. 11.4%
## 7 L'essentiel 2017 330524454 112. 11.9%
## 8 L'essentiel 2018 356325942 121. 20.6%
## 9 Le Jeudi 2015 1968250 100 0.0%
## 10 Le Jeudi 2016 1151705 58.5 -41.5%
## # … with 23 more rowscim4 %>%
select(1:10) %>%
filter(date >= "2015-01-01") %>%
# filter(category == "News") %>%
filter(metrics %in% c("pages_view", "sessions")) %>%
filter(site != "Luxtimes.lu") %>%
group_by(site,year, metrics) %>%
mutate(cum_sum = cumsum(hits)) %>%
summarise(sum_page = max(cum_sum)) %>%
ungroup() %>%
group_by(site, metrics) %>%
mutate(base100 = (sum_page/first(sum_page)) * 100) %>%
mutate(t = (base100 - 100)/100) %>%
mutate(label = case_when(last(base100) >= 100 ~ "2018 > 2015", last(base100) < 100 ~ "2018 < 2015")) %>%
ggplot() +
aes(year, base100, group = metrics) +
geom_hline(yintercept = 100, col = "black", size = 0.7) +
scale_y_continuous(limits = c(-500, 600)) +
geom_line(aes(col = metrics), size = 0.5) +
geom_point(aes(col = metrics),size = 1, alpha = 1) +
ggthemes::theme_solarized_2() +
theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm"), axis.ticks = element_blank(), axis.text.x = element_text(angle = 90, size = 8), strip.text.x = element_text(angle=90, hjust = 0)) +
labs(title = paste("Evolution des pages vues et sessions (base100 en 2015)"), subtitle = "Du 01.01.2015 au 31.12.2018", x = "", y = "Base 100", caption = "Data source : CIM, cim.be - © DARP - www.davidsolito.com - 2018") +
facet_grid(. ~ site)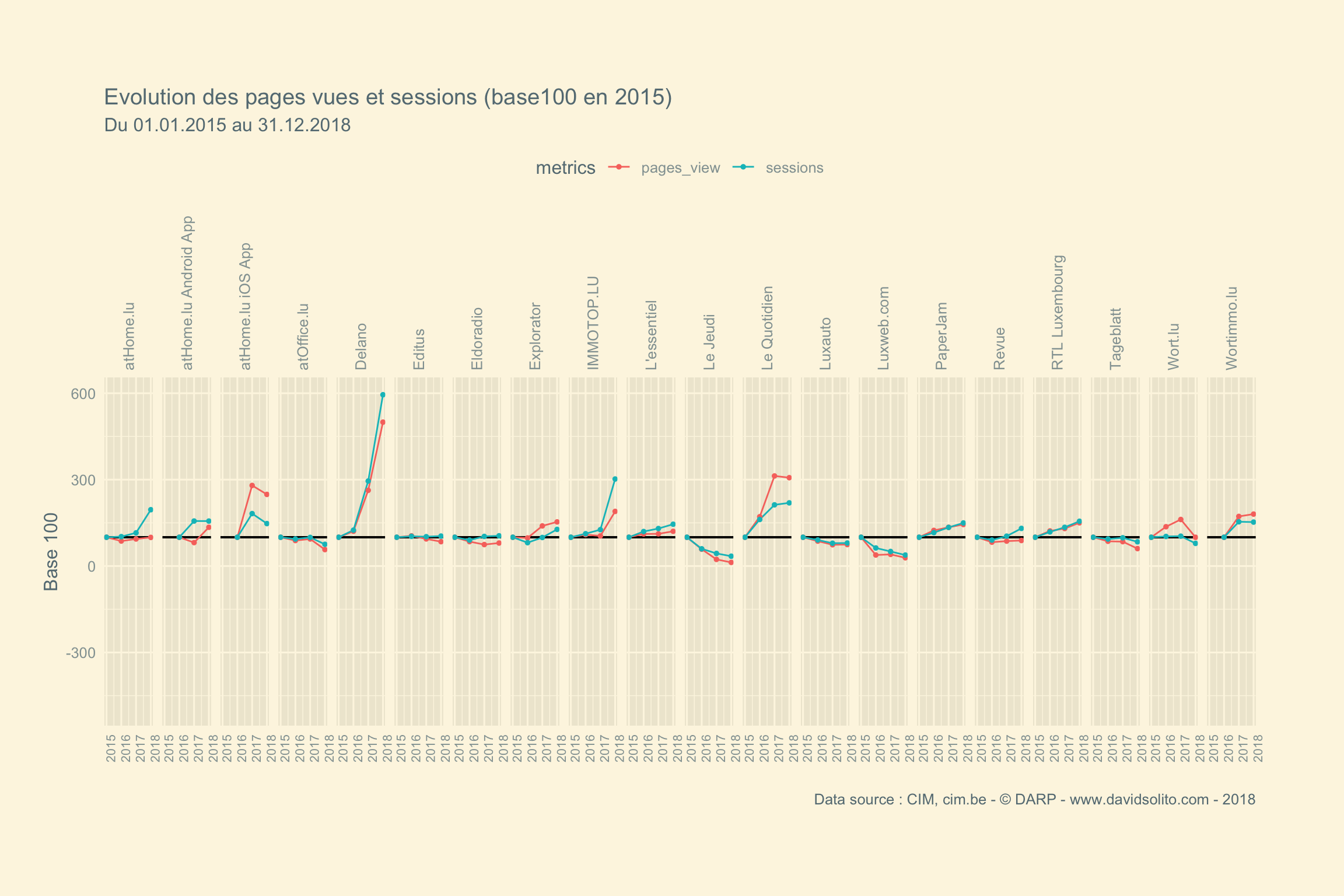
Bravo à Delano pour cette progression !
Appendix