Scraping CIM avec Purrr
Reading time ~ 5 minutes ->
Aujourd’hui nous allons extraire les statistiques d’audiences des principaux sites luxembourgeois à partir du site CIM. Le but du CIM est de fournir des informations précises objectives et fiables à l’objectivation et l’optimisation des investissements publicitaires en Belgique et accessoirement au Luxembourg. Pour plus d’informations, vous pouvez consulter le site ici.
Nous allons nous concentrer sur l’étude d’audience et les résultats au Luxembourg. Malheureusement, le CIM ne publie les résultats que de manière journalière. Nous allons donc développer une fonction de scraping afin de récupérer l’ensemble des statistiques sur les dernières années. Vous pouvez consulter la page des résultats ici.
GET the Call
Les résultats sont générés via ajax lors d’une requête de résultat par une URL et GET pour un jour donné. Afin d’afficher cette URL, c’est assez facile sous chrome:
- Inspecter la page mentionnée plus haut
- Allez dans “Network”
- Afficher les résultats
- Cliquer sur le jour précédant
- Cliquez dans la colonne de gauche pour afficher l’URL.
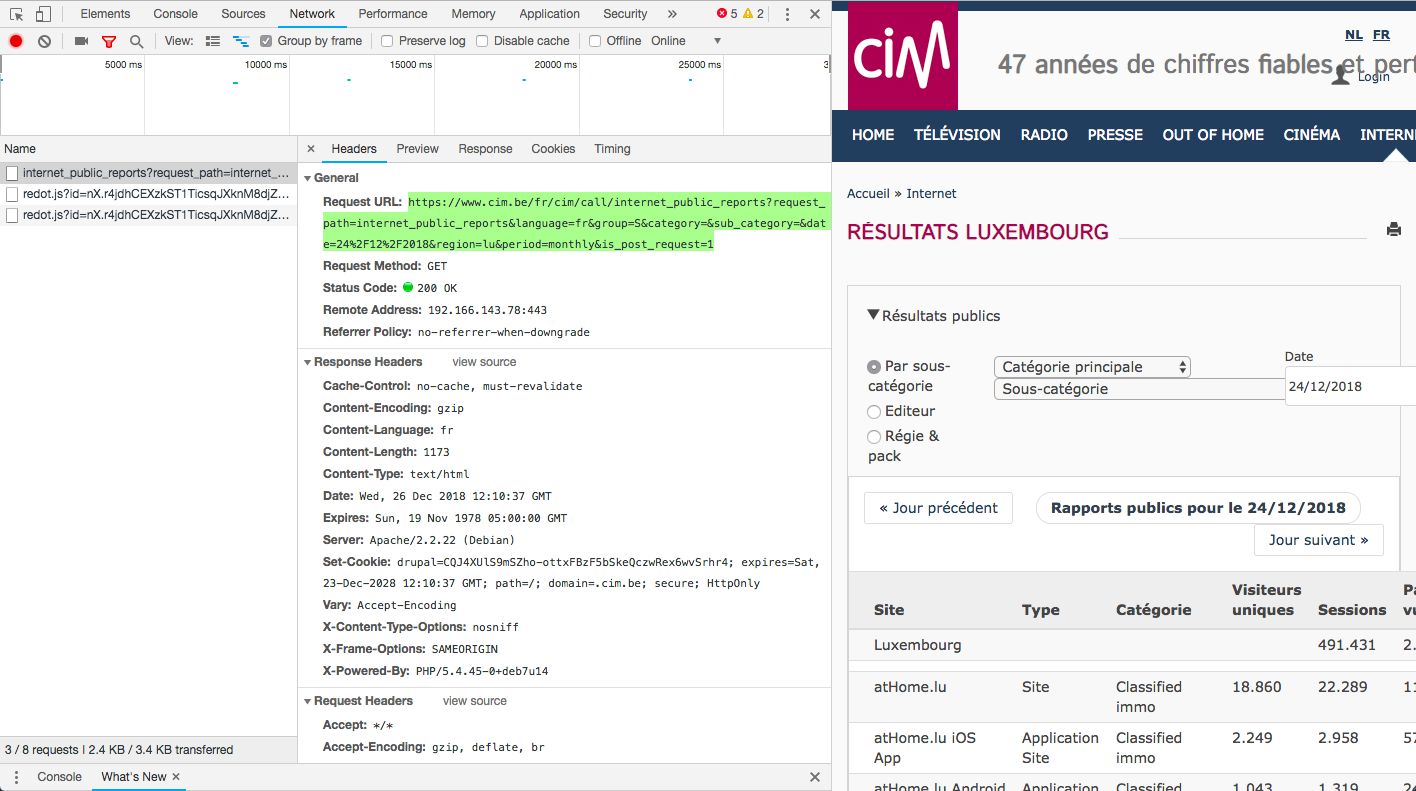
Pour vous faciliter le travail, voici directement l’URL appelée : Résultat du 24.12.2018. Vous pouvez constater dans l’URL la date du jour séparée par %2F. Il s’agit d’une URL encoding, c’est-à-dire la transformation d’un caractère, ici le / en URL. L’encodage transforme donc la date 24/12/2018 en 21%2F11%2F2017.
Workflow
Nous allons établir un workflow. L’idée de décrire un workflow me permet simplement de réfléchir aux étapes dans la programmation de l’algorithme.
- Fonction Scraping de la table de la page affichée (selon la date)
- Création d’une liste de date pour le scraping
- Itérer la fonction de scraping sur la liste de date
- Transformation en data.frame et cleaning de la table
- Application
Pour compliquer un peu, nous voulons avoir une fonction qui retourne l’ensemble des mesures à partir d’une date donnée jusque-là date du jour -1. Nous devrons donc séquencer le processus à l’intérieur même de la fonction : séquence de date, création des URLs, scraping, cleaning et transformation des données récoltées.
Librairies
Chargeons les librairies nécessaires. Il nous faut:
tidyverse, purrr, dplyr et tout le reste d’utile!
httr, pour converser avec le server http.
rvst, pour les fonctions de scraping et d’extract de nodes xml.
lubridate pour les fonctions de parsing de date Janitorpour le cleaning skimrpour une synthèse sommaire de la base de donnée.
library(httr)
library(rvest)
library(tidyverse)
library(lubridate)
library(janitor)
library(skimr)
library(ggthemes)1. Get the first Table
La fonction read_htmlpermet de lire le contenu d’une page HTML.
read_html("https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=24%2F12%2F2018®ion=lu&period=monthly&is_post_request=1")## {xml_document}
## <html>
## [1] <body><div class="panel panel-default">\n <!--<div class="panel-hea ...A cela nous ajoutons la fonction html_table qui permet de transposer directement une table HTML en une list. 2 paramètres sont utilisés ici : trim et dec. Afin d’éviter une transformation des mesures de la table en numérique, je préfère les laisser en caractère pour éviter les erreurs. En effet, certaines valeurs sont composées de 2 “.”, comme par ex : 1.234.231 de pages vues.
read_html("https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=24%2F12%2F2018®ion=lu&period=monthly&is_post_request=1") %>%
html_table(trim = TRUE, dec = "")## [[1]]
## Site Type Catégorie
## 1 Luxembourg
## 2
## 3 atHome.lu Site Classified immo
## 4 atHome.lu iOS App Application Site Classified immo
## 5 atHome.lu Android App Application Site Classified immo
## 6 atOffice.lu Site Classified immo
## 7 Delano Site News
## 8 Editus Site Service directories
## 9 Eldoradio Site Culture & entertainment radio
## 10 Explorator Site Service directories
## 11 IMMOTOP.LU Site Classified immo
## 12 L'essentiel Site News
## 13 Le Jeudi Site News
## 14 Le Quotidien Site News
## 15 Luxauto Site Classified automotive
## 16 Luxtimes.lu Site News
## 17 Luxweb.com Site Portal
## 18 PaperJam Site B2b
## 19 Revue Site News
## 20 RTL Luxembourg Site News
## 21 Tageblatt Site News
## 22 Wort.lu Site News
## 23 Wortimmo.lu Site Classified immo
## Visiteurs uniques Sessions Pages vues
## 1 491.431 2.273.641
## 2
## 3 18.860 22.289 113.975
## 4 2.249 2.958 57.410
## 5 1.043 1.319 24.033
## 6 156 169 1.096
## 7 727 790 1.593
## 8 17.429 19.803 39.594
## 9 8.961 14.563 68.762
## 10 257 277 837
## 11 8.414 9.167 38.096
## 12 74.077 117.846 550.375
## 13 158 167 278
## 14 3.763 4.187 15.019
## 15 8.274 11.030 143.625
## 16 3.007 3.376 6.124
## 17 1.241 1.362 3.495
## 18 3.897 4.410 10.448
## 19 204 233 423
## 20 113.142 217.620 993.959
## 21 8.473 10.248 32.904
## 22 35.520 44.919 153.264
## 23 4.182 4.698 18.331Nous allons composer une fonction à partir des deux fonctions précédentes. Avant cela, enregistrons l’URL dans un vecteur. La fonction compose permet de composer une fonction à partir de plusieurs autres fonctions, la fonction partial permet de créer une nouvelle fonction à partir d’une autre, mais avec ces propres paramètres.
url_test <- "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=24%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
read_table <- partial(html_table, trim = TRUE, dec = "")
get_cim_table <- compose(read_table, read_html)
get_cim_table(url_test)## [[1]]
## Site Type Catégorie
## 1 Luxembourg
## 2
## 3 atHome.lu Site Classified immo
## 4 atHome.lu iOS App Application Site Classified immo
## 5 atHome.lu Android App Application Site Classified immo
## 6 atOffice.lu Site Classified immo
## 7 Delano Site News
## 8 Editus Site Service directories
## 9 Eldoradio Site Culture & entertainment radio
## 10 Explorator Site Service directories
## 11 IMMOTOP.LU Site Classified immo
## 12 L'essentiel Site News
## 13 Le Jeudi Site News
## 14 Le Quotidien Site News
## 15 Luxauto Site Classified automotive
## 16 Luxtimes.lu Site News
## 17 Luxweb.com Site Portal
## 18 PaperJam Site B2b
## 19 Revue Site News
## 20 RTL Luxembourg Site News
## 21 Tageblatt Site News
## 22 Wort.lu Site News
## 23 Wortimmo.lu Site Classified immo
## Visiteurs uniques Sessions Pages vues
## 1 491.431 2.273.641
## 2
## 3 18.860 22.289 113.975
## 4 2.249 2.958 57.410
## 5 1.043 1.319 24.033
## 6 156 169 1.096
## 7 727 790 1.593
## 8 17.429 19.803 39.594
## 9 8.961 14.563 68.762
## 10 257 277 837
## 11 8.414 9.167 38.096
## 12 74.077 117.846 550.375
## 13 158 167 278
## 14 3.763 4.187 15.019
## 15 8.274 11.030 143.625
## 16 3.007 3.376 6.124
## 17 1.241 1.362 3.495
## 18 3.897 4.410 10.448
## 19 204 233 423
## 20 113.142 217.620 993.959
## 21 8.473 10.248 32.904
## 22 35.520 44.919 153.264
## 23 4.182 4.698 18.3312. List of date, une fonction anonyme, avec mapper et compose
Afin de pouvoir scraper l’ensemble des tables, il nous faut une liste de dates. Nous allons travailler avec la fonction dmy() du package lubridate couplé à la fonction seq. Nous pouvons choisir l’incrément de la séquence en jour, semaines, mois… Ici nous avons besoin des tables pour chaque jour. Étant donné que les dernières statistiques sont celles de la veille, nous retirons un jour à la date du jour. Nous formatons ensuite les dates selon nos besoins, à savoir : jour, mois, année. Commençons par la séquence :
format(seq(dmy("24/12/2018"), as.Date(today() -1 ), "day"), "%d-%m-%Y")## [1] "24-12-2018" "25-12-2018" "26-12-2018" "27-12-2018" "28-12-2018"
## [6] "29-12-2018" "30-12-2018" "31-12-2018" "01-01-2019"2.1. Sous une fonction
Créons une fonction. N’oublions pas comme nous l’avons vu plus haut, nous ne pouvons pas utiliser le format de date de cette manière. Nous devons encoder les dates avec l’encoder URL.
create_cim_date <- function(x) {
date <- dmy(x)
yesterday <- today() -1
seq <- seq(date, yesterday, "day")
seq <- format(seq, "%d-%m-%Y")
str_replace_all(seq, "-", "%2F")
}2.2. Avec as_mapper
Sous forme de mapper : la fonction as_mapper permet de créer une fonction anonyme via une formule.
create_cim_date <- as_mapper( ~ str_replace_all(format(seq(dmy(.x), today() -1, "day"), "%d-%m-%Y"),"-", "%2F"))
## Il faut voir ici si il est nécessaire de créer une liste de dates ou plusieurs liste d'une date??2.3. Avec compose
Avec compose pour plus de lisibilité. Nous composons une fonction sur base de plusieurs fonctions. L’avantage c’est que nous pouvons composer 2 fonctions, une avec encodage et l’autre sans encodage (que nous utiliserons plus tard).
cim_seq <- as_mapper(~ seq(dmy(.x), as.Date(today() -1 ), "day"))
cim_format <- as_mapper(~ format(.x, "%d-%m-%Y"))
cim_encode <- as_mapper(~ str_replace_all(.x, "-", "%2F"))
# composistion of 2 functions
create_cim_date <- compose(cim_format, cim_seq)
create_cim_encoded_date <- compose(cim_encode, cim_format, cim_seq) Testons le résultat. L’avantage de la fonction dmy() c’est qu’elle autorise différentes façons d’écrire la date en input :
- “01/11/2018”
- “01.11.2018”
- “01112018”
create_cim_date("25.12.2018")## [1] "25-12-2018" "26-12-2018" "27-12-2018" "28-12-2018" "29-12-2018"
## [6] "30-12-2018" "31-12-2018" "01-01-2019"Version encodée.
create_cim_encoded_date("25.12.2018")## [1] "25%2F12%2F2018" "26%2F12%2F2018" "27%2F12%2F2018" "28%2F12%2F2018"
## [5] "29%2F12%2F2018" "30%2F12%2F2018" "31%2F12%2F2018" "01%2F01%2F2019"3. Creation des URL’s
Nous allons maintenant procéder à la création des URLs nécessaires. Décomposons l’URL en 3 parties. La base, la date puis la fin de l’URL complète, soit :
- url_1part + date + url_2part
cim_url_1part <- "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date="
cim_url_2part <- "®ion=lu&period=monthly&is_post_request=1"
create_cim_url <- as_mapper(~ paste0(cim_url_1part, create_cim_encoded_date(.x), cim_url_2part))Testons la création d’URL. Le résultat est celui attendu. 2 URLs générées avec encodage de la date.
create_cim_url("251218")## [1] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=25%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [2] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=26%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [3] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=27%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [4] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=28%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [5] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=29%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [6] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=30%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [7] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=31%2F12%2F2018®ion=lu&period=monthly&is_post_request=1"
## [8] "https://www.cim.be/fr/cim/call/internet_public_reports?request_path=internet_public_reports&language=fr&group=S&category=&sub_category=&date=01%2F01%2F2019®ion=lu&period=monthly&is_post_request=1"4. Création de la fonction principale et cleaning de la sortie
Nous allons utiliser les fonctions créées précédemment pour la dernière fonction. Pour rappel :
get_cim_url() -> pour créer la liste des URLs à partir d’une date donnée,
get_cim_table() -> pour récupérer les tables des URLs.
Nous utilisons la fonction map() pour itérer la fonction get_cim_table() sur la liste des URLs. Nous appliquons la date de la page comme nom pour les index de la liste. Puis nous transformerons l’ensemble des listes en une seule table avec la fonction map_df + bind_rows. Le paramètre .id permet l’enregistrement de la date de chaque liste dans une nouvelle colonne. Nous supprimons les rangées vides et avec comme entrée “Luxembourg”. Nous transformons les colonnes en “date” et les mesures d’audience en numérique. Enfin, nous appliquons la fonction gather() pour transformer la table en table tidy.
get_cim_data <- function(x) {
create_cim_url(x) %>%
map(get_cim_table) %>%
set_names(create_cim_date(x)) %>%
map_df(bind_rows, .id = "date") %>%
clean_names() %>%
filter(site != "Luxembourg") %>%
filter(site != "") %>%
mutate_at(c("sessions", "visiteurs_uniques", "pages_vues"), str_remove_all, "\\.") %>%
mutate_at(c("visiteurs_uniques", "sessions","pages_vues"), as.numeric) %>%
mutate(date = dmy(date)) %>%
mutate(pages_by_session = round(pages_vues/sessions, 1)) %>%
mutate(sessions_by_user = round(sessions/visiteurs_uniques, 1)) %>%
rename(unique_visitors = visiteurs_uniques, pages_view = pages_vues, category = categorie) %>%
gather(key = dim, value = hits, c(5:9)) %>%
distinct() %>%
as.tibble()
}5. Possibly, au secours !
Il se peut que certaines dates ne contiennent pas de pages pouvant provoquer l’arrêt du processus de scraping, voir même un message d’erreur du serveur lors de la requête. Nous utiliserons dès lors la fonction possiblydu package purrr. Possibly permet de transformer une fonction de sorte que le processus ne s’arrête pas en cas d’erreur, mais enregistre dans la liste l’erreur générée et poursuive son itération (via la fonction map()). Il faut donc :
- Générer une nouvelle fonction avec
possibly. Nous indiquons ici l’output avec le paramètreotherwiseen cas d’erreur. Dans ce cas-ci cela seraNULL.
possibly_get_cim_table <- possibly(get_cim_table, otherwise = NULL)- Nous ne conservons que les dates n’ayant généré aucune erreur avec la fonction
discard+is.null(). Voici la fonction complète et fonctionnelle.
get_cim_data <- function(x) {
create_cim_url(x) %>%
map(possibly_get_cim_table) %>% # <- Use the possibly function
set_names(create_cim_date(x)) %>%
discard(~ is.null(.x)) %>% # <- discard NULL value
map_df(bind_rows, .id = "date") %>%
clean_names() %>%
filter(site != "Luxembourg") %>%
filter(site != "") %>%
mutate_at(c("sessions", "visiteurs_uniques", "pages_vues"), str_remove_all, "\\.") %>%
mutate_at(c("sessions", "visiteurs_uniques", "pages_vues"), as.numeric) %>%
mutate(date = dmy(date)) %>%
filter(visiteurs_uniques != 0) %>%
mutate(pages_by_session = round(pages_vues/sessions, 1)) %>%
mutate(sessions_by_user = round(sessions/visiteurs_uniques, 1)) %>%
rename(unique_visitors = visiteurs_uniques, pages_view = pages_vues, category = categorie) %>%
gather(key = dim, value = hits, c(5:9)) %>%
as.tibble()
}6. Application de la fonction
Testons la fonction avec la date du 01/01/2011. La transformation de la fonction en possibly_get_cim_table nous à permis de ne conserver que les tables existantes. Il a fallu un peu plus d’1h pour récupérer l’ensemble des données.
Nous voyons effectivement que la première observation commence le 30.03.2011 et non le 01.01.2011. C’est effectivement juste, car il n’existe aucun tableau pour les dates antérieures au 30.03. Nous avons donc 244,345 observations. Nous pourrons compléter cette base avec les jours à venir. La fonction skim() du package skimr offre une belle vue synthétique de notre base de données. Vous avez même droit à un histogramme pour les variables de type numérique :-)
cim_2011 %>%
skim()## Skim summary statistics
## n obs: 244345
## n variables: 6
##
## ── Variable type:character ─────────────────────────────────────────────────────
## variable missing complete n min max empty n_unique
## category 0 244345 244345 3 29 0 7
## dim 0 244345 244345 8 16 0 5
## site 0 244345 244345 5 21 0 21
## type 0 244345 244345 4 16 0 2
##
## ── Variable type:Date ──────────────────────────────────────────────────────────
## variable missing complete n min max median
## date 0 244345 244345 2011-03-30 2018-12-25 2015-08-28
## n_unique
## 2694
##
## ── Variable type:numeric ───────────────────────────────────────────────────────
## variable missing complete n mean sd p0 p25 p50 p75
## hits 0 244345 244345 44993.27 213151.46 0.5 2.8 667 15287
## p100 hist
## 2.7e+07 ▇▁▁▁▁▁▁▁7. Save the DB
Nous sauvegardons enfin le fichier sur le disque avec la fonction saveRDS. Elle à l’avantage de compresser le fichier. De plus, lors d’un chargement ultérieur du fichier, vous avez la possibilité de nommer à votre guise la table dans l’environnement de travail.
saveRDS(cim_2011, file = "cim_30-03-2011_25-12-2018.rds")8. This is not the end, my friend
Nous avons exploré plusieurs fonctions du package purrr comme :
map()map_df()set_names()discard()possibly()compose()
as_mapper()
Mais aussi entre autres :
clean_names()du packagejanitorskim()du packageskimr
ymd()du packagelubridate
Le processus de la fonction get_cim_data() suit le workflow que nous avions décrit au début de l’article.
8. First Graph
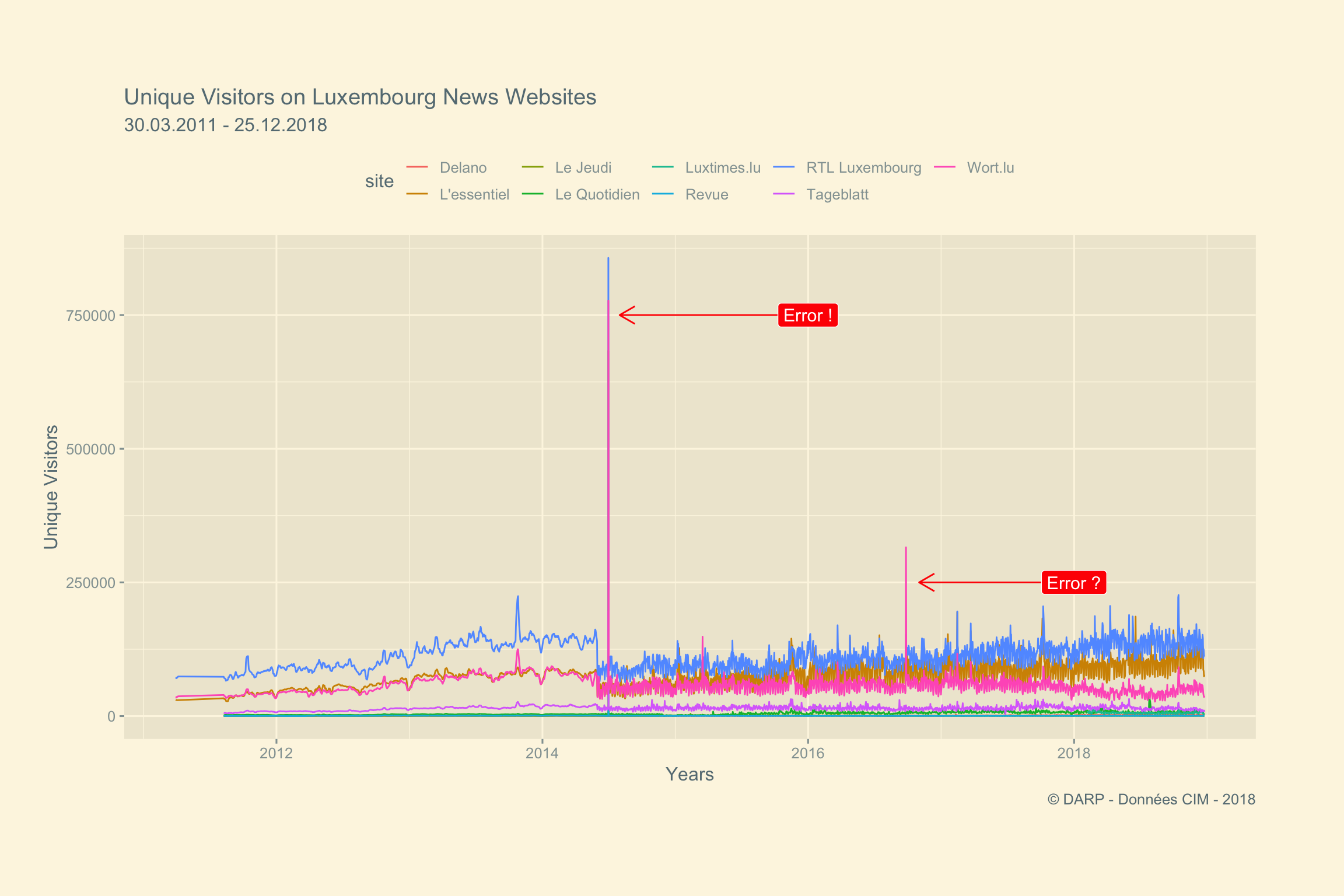
Premier graphique. Houuurraaa. Les données sont bien exploitables. Nous remarquons néanmoins quelques anomalies ainsi qu’une chute des valeurs après 2014. La première hypothèse que j’ai est que la méthodologie de mesure à changé, sans doute pour plus de précision…
cim_2011 %>%
filter(category == "News") %>%
filter(dim == "unique_visitors") %>%
ggplot() +
aes(date, hits, col = site) +
geom_line() +
annotate("segment", x = as.Date("2016-01-01"), xend = as.Date("2014-08-01"), y = 750000, yend = 750000, colour = "red", size = 0.5, arrow = arrow(length = unit(0.4, "cm"))) +
annotate("segment", x = as.Date("2018-01-01"), xend = as.Date("2016-11-01"), y = 250000, yend = 250000, colour = "red", size = 0.5, arrow = arrow(length = unit(0.4, "cm"))) +
annotate(x= as.Date("2016-01-01"), y = 750000, geom = "label", fill = "red", col = "white", label = "Error !", size = 4) +
annotate(x= as.Date("2018-01-01"), y = 250000, geom = "label", fill = "red", col = "white", label = "Error ?", size = 4) +
theme_solarized_2() +
theme(legend.position = "top", plot.margin = unit(c(2,2,2,1), "cm")) +
labs(title = "Unique Visitors on Luxembourg News Websites",
x = "Years",
y = "Unique Visitors",
subtitle = "30.03.2011 - 25.12.2018",
caption = " © DARP - Données CIM - 2018")